Preface
These are my sloppy personal notes as I prepare to take the final Linux+/LPIC1 exam. This will be replaced (in time) with better notes.
Display Managers
LightDM
- LightDM’s main configuration file is
/etc/lightdm/lightdm.conf:- The main section is:
[SeatDefaults] - Common options within this section include:
greeter-session=name— sets a greeter (i.e. a welcome screen).- The
namevalue is the name of the*.desktopfile in the/usr/share/xgreeters/directory.
- The
user-session=name— sets a user environment (i.e. a desktop environment).- The
namevalue is the name of the*.desktopfile in the/usr/share/xsessions/directory.
- The
allow-guest=true— enables guest login.greeter-show-manual-login=true— shows a field to type in a username.greeter-hide-users=true— hides user selection.autologin-user=user— automatically logs in as user.autologin-user-timeout=30— automatic logs in after 30 seconds.
/etc/lightdm/lightdm.conf.d/contains many sub-configuration files.
- The main section is:
GDM3
- Main configuration file is
/etc/gdm3/custom.conf:[daemon]section:AutomaticLoginEnable=True— enables automatic login.AutomaticLogin=user— auto login as user.WaylandEnable=false— disables Wayland and uses Xorg X11 instead.
[security]section:DisallowTCP=false— re-enables TCP, useful for X11Forwarding without SSH.
X
- Protocol is XDMCP (X Display Manager Control Protocol)
on port 177 UDP incomming and ports 6000-6005 TCP bidirectional. - Five XDMCP servers are common:
- XDM
- KDM
- GDM
- LightDM
- MDM
xorg.conf file
- Major sections
- Module
- InputDevice
- Monitor
- Device
- Screen
- ServerLayout
- Module handles loading X server modules via Load.
- InputDevice configures the keyboard and mouse.
- Identifier is a label.
- Driver is the driver to be used for the device (ex.
kbd, mouse, Keyboard, evdev, etc.). - Option sets various options for the device (ex.
Device, Protocol, AutoRepeat, etc.). - Device is usually one of these:
- “/dev/input/mice”
- “/dev/input/mouse1”
- “/dev/usb/usbmouse”
- “/dev/ttyS0”
- “/dev/ttyS1”
- Protocol is the signal X can expect from
the mouse movements and button presses.- “Auto”
- “IMPS/2”
- “ExplorerPS/2”
- “PS/2”
- “Microsoft”
- “Logitech”
- InputDevice configures the keyboard and mouse.
- Monitor section can specify HorizSync, VertRefresh, and
Modeline of the monitor.- Identifier and ModelName can be anything you want.
- HorizSync is in kilohertz (kHz).
- VertRefresh is in hertz (Hz).
- Modeline can be acquired from
cvt <h-resolution> <v-resolution> <refreshRate>. - A new modeline can be added with
xrandr --newmode <modeline>. - Monitor name can be retrieved with `xrandr -q`.
- Device section typically defines the video card being used.
- Identifier, VendorName, and BoardName can be anything
you want. - Driver can be any of the modules that exist in
/usr/lib/xorg/modules/drivers/. VideoRamisn’t necessary to define, but it’s the
amount of RAM in kilobytes.
- Identifier, VendorName, and BoardName can be anything
- Screen section defines the combination of monitor and
video cards being used.- Identifier can be anything.
- Device must match the Identifier from the Device section.
- Monitor must match the Identifier from the Monitor section.
- DefaultDepth is the default SubSection to use based on color depth (32 bit is the greatest depth possible).
- SubSection “Display” defines a display option X may use.
- Depth is the color depth in bits.
- Modes is the modeline (generated by `cvt`)
- EndSubSection completes a subsection.
- ServerLayout section links all the other sections together.
- Identifier can be anything you want.
- Screen is the Identifier(s) in the Screen section.
- InputDevice is the Identifier(s) in the InputDevice
section.
- Files section is used to add fonts and font paths.
- FontPath will define a path to look for fonts.
Fonts
- Font paths can be added in the
xorg.conffile using the Files section, appended withxset fp+ </font/directory>, or prepended withxset +fp </font/directory>. - To have linux re-examine the font path, use
xset fp rehash. - Available fonts may be checked using the
xfontselcommand. - Font servers can be added to the
xorg.confFile section (ex.FontPath "tcp/test.com:7100"). - Default fonts can be adjusted in KDE by typing
systemsettingsin a terminal.
Accessibility
- AccessX was the common method for enabling/editing accessibility options. It has been deprecated but is specifically mentioned on the exam.
- Sticky keys make modifier keys “stick” when pressed, and affect the next regular key to be pressed.
- Can be enabled on GNOME by pressing
shiftkey five times in a row.
- Can be enabled on GNOME by pressing
- Toggle keys play a sound when the locking keys are pressed.
- Mouse keys enables the numpad to act as a mouse.
- Bounce/Debounce keys prevent accidentally pressing a single key multiple times.
- Slow keys require a key to be held longer than a set period of time for it to register a key press.
- Keyboard Repeat Rate determines how quickly a key repeats when held down.
- Time Out sets a time to stop accessibility options automatically.
- Simulated Mouse Clicks can simulate a mouse click whenever the cursor stops moving, or simulate a double click whenever the mouse button is pressed for an extended period.
- Mouse Gestures activate program options by moving your mouse in a specific pattern.
- Sticky keys make modifier keys “stick” when pressed, and affect the next regular key to be pressed.
- GNOME On-Screen Keyboard (GOK) was the onscreen option for GNOME desktop, but has been replaced with Caribou.
- Default fonts can be adjusted in KDE by typing
systemsettingsin a terminal. kmagcan be used to start the KMag on-screen magnifier.- Speech synthesizers for Linux include:
- Orca — integrated in GNOME 2.16+.
- Emacspeak — similar to Orca.
- The BRLTTY project provides a Linux daemon to redirect text-mode console output to a Braille display.
- Since kernel 2.6.26, direct support for Braille displays exists on Linux.
Cron Jobs
- Syntax is:
- Minute of hour (0-59)
- Hour of day (0-23)
- Day of month (1-31)
- Month of year (1-12)
- Day of week (0-7)
0and7are both Sunday.
- Note: Values may be separated by commas or divided by a number (ex.
*/15or0,15,30,45).
/etc/cron.allowdetermines which users are allowed to create cron jobs./etc/cron.denyblocks listed users from creating cron jobs.- System cron jobs are run from the
/etc/crontabfile.- Crontab syntax is:
moh hod dom moy dow user command
- Crontab syntax is:
- Scripts can be placed within the following directories to be automatically processed by the entries in the crontab file:
/etc/cron.hourly//etc/cron.daily//etc/cron.weekly//etc/cron.monthly/
- On Debian systems, any files within the
/etc/cron.d/directory are treated as additional crontab files. - User cron jobs are stored in a file at
/var/spool/cron/crontabs/user. - Use the
crontabcommand to edit the jobs in the /var/spool/cron/crontabs/ directory.-uspecifies the user.-llists all current jobs.-eedits the crontab file.-rremoves the current crontab.-irinteractive prompts for removal
at
atwill execute commands at a specified time.- Do not directly pass a command to the
atcommand.- First enter the
atcommand with a specified time. - An interactive
at>prompt will appear. - Enter all commands desired.
- Press
^dto send the EOF input to complete the job submission.
- First enter the
- Accepts the following time strings:
now|hh am|hh pm + value minutes|hours|days|weekstodaytomorrowHHMMHH:MMMMDD[CC]YYMM/DD/[CC]YYDD.MM.[CC]YY[CC]YY-MM-DD- Examples:
at 4pm + 3 daysat 10am Jul 31at 1am tomorrow
-msend mail to the user when the job completes.-Mnever mail the user.-fread the job from a file.-trun the job at a specific time.- [[CC]YY]MMDDhhmm[.ss]
-llist all jobs queued.- Alias for
atq.
- Alias for
-rremove a job.- Alias for
atrm.
- Alias for
-ddelete a job.- Alias for
atrm.
- Alias for
- Do not directly pass a command to the
atqqueries and lists all jobs currently scheduled and their job IDs.atrmremoves jobs by ID.- Access to the
atcommand can be restricted with/etc/at.allowand/etc/at.deny.
anacron
- Similar to cron but runs periodically when available, rather than at specific times. This makes it useful for systems that are not running continuously.
/var/spool/anacronis where timestamps from anacron jobs are stored.- When
anacronis executed, it reads a list of jobs from a configuration file at/etc/anacrontab.- Each job specifies:
- Period in days
@daily@weekly@monthly- numeric value
1-30
- Delay in minutes
- Unique job identifier name
- Shell commands
- Example:
1 5 cron.daily run-parts --report /etc/cron.daily7 10 cron.weekly run-parts --report /etc/cron.weekly@monthly 15 cron.monthly run-parts --report /etc/cron.monthly
- Period in days
-fforces execution of jobs, regardless of timestamps.-uupdates the timestamps without running.-sserialize jobs — a new job will not start until the previous one is finished.-nnow — run jobs immediately (implies-sas well).-ddon’t fork to background — output informational messages to STDERR, as well as syslog.-qquiet messages to STDERR when using-d.-tspecify a specific anacrontab file instead of the default.-Ttests the anacrontab file for valid syntax.-Sspecify the spooldir to store timestamps in. Useful when running anacron as a regular user.
- Each job specifies:
run-parts
- Executes scripts within a directory.
- Used often in crontab and anacrontab to execute scripts within the cron.daily, cron.weekly, cron.monthly, etc. directories.
Time
- Linux uses Coordinated Universal Time (UTC) internally.
- UTC is the time in Greenwich, England, uncorrect for daylight savings time.
Timezone
- Linux uses the
/etc/localtimefile for information about its local time zone./etc/localtimeis not a plain-text file, and is typically a symlink to a file in/usr/share/zoneinfo/.- Example:
$ ll /etc/localtime
lrwxrwxrwx 1 root root 35 Jun 24 03:02 /etc/localtime -> /usr/share/zoneinfo/America/Phoenix
- Example:
- Debian based distributions also use
/etc/timezoneto store text-mode time zone data. - Redhat based distributions also use
/etc/sysconfig/clockto store text-mode time zone data. - A user can set their individual timezone using the TZ environment variable.
export TZ=:/usr/share/zoneinfo/timezone- std offset can be used in place of
:/usr/share/zoneinfo.- When daylight savings is not in effect.
std offset- Ex.
MST+3
- When daylight savings is in effect:
- std offset dst[offset],start[/time],end[/time]
- Ex.
MST+3EST,M1.19.0/12,M4.20.0/12
- When daylight savings is not in effect.
Locale
- A locale is a way of specifying the machine’s/user’s language, country, and other information for the purpose of customizing displays.
- Locales take the syntax of:
[language[_territory][.codeset][@modifier]]- language is typically a two or three-letter code (
en,fr,ja, etc.) - territory is typically a two letter code (
US,FR,JP, etc.). - codeset is often
UTF-8,ASCII, etc. - modifier is a locale-specific code that modifies how it works.
- language is typically a two or three-letter code (
- Locales take the syntax of:
- The
localecommand can be used to view your current locale.LC_ALLis kind of like a master override — if it is set, all otherLC_*variables are overridden by it.LANGwill be used as a default for anyLC_*variables that are not set.- Setting
LANG=Cprevents programs from passing their output through locale translations.
- Setting
locale -ashows all available locales on the system.
- The
iconvcommand can be used to convert between character sets.iconv -f encoding [-t encoding] [inputfile]...-fis the source encoding.-tis the destination encoding.
- Ex.
iconv -f iso-8859-1 -t UTF-8 german-script.txt
hwclock
hwclockis used to synchronize the hardware clock with the system clock.-r/--showwill show the current hardware clock time:Thu 02 Aug 2018 01:46:09 AM MST -0.329414 seconds
-s/--hctosyswill set system time from hardware clock.-w/--systohcwill set the hardware clock from system time.
date
datedisplays the current date and time.- Accepted datetime format is
MMDDhhmm[[CC]YY][.ss]]-d/--date=sets the date and time.- Defaults to
nowif not used.
- Defaults to
-s/--set=sets time to provided value.-u/--utc/--universalprint or set time in Coordinated Universal Time (UTC).
- Output can be formatted with
date +"%format":%a– abbreviated weekday name (Mon)%A– non-abbreviated weekday name (Monday)%b– abbreviated month name (Jan)%B– non-abbreviated month name (January)%c– locale’s date and time (Thu Aug 2 00:10:29 2018)%C– century (20)%d– day of month (01)%D– date; same as%m/%d/%y(8/2/18)%e– day of month with space padding; same as%_d(01)%F– full date; same as%Y-%m-%d(2018-8-2)%H– hour (00 - 23)%I– hour (01 - 12)%j– day of year (001 - 366)%k– hour with space padding; same as%_H(21)%l– hour with space padding; same as%_I(09)%m– month (01 - 12)%M– minute (00 - 59)%n– newline%N– nanoseconds%p– locale’s equivalent ofAM/PM%P– same as%p, but lowercase%q– quarter of year (1 - 4)%r– locale’s 12 hour clock (12:16:43 AM)%R– 24 hour clock; same as%H:%M(00:16)%s– seconds since January 1st, 1970 UTC%S– second (00 - 60)%t– tab%T– time; same as %H:%M:%S (00:23:53)%u– day of week (1 - 7);1is Monday%U– week number of year, starting on Sunday (00 - 53)%w– day of week (0 - 6);0is Sunday%W– week number of year, starting on Monday (00 - 53)%x– locale’s date representation (8/2/18)%X– locale’s time representation (00:19:43)%y– last two digits of year (00 - 99)%Y– year%z– +hhmm numeric time zone (-0400)%Z– time zone abbreviation (MST)- Example:
date +"%A %B %d, %Y - %I:%M:%S %p"
Thursday August 02, 2018 – 12:30:45 AM
NTP
- The NTP daemon is responsible for querying NTP servers listed in
/etc/ntp.conf.- Example:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
- Example:
- The
ntpdatecommand synchronizes time with the NTP servers but is deprecated in favor ofntpd -gq.- Note:
ntpdmust be stopped in order forntpd -gqto work:ntpd: time slew -0.011339s
- Note:
- The
ntp.driftfile is responsible for adjusting the system’s clock as clock drift occurs, and is typically stored in/var/lib/ntp/or/etc/. - The
ntpqcommand opens an interactive mode for ntpd, with anntpq>prompt.ntpq> peersshows details about the NTP servers in use.refidis the server to which each system is synchronized.stis the stratum number of the server.- Note:
ntpq -p/ntpq --peersfunctions the same without being in an interactive prompt.
ssh
ssh-addis used to add an RSA/DSA key to the list maintained by ssh-agent (ex. ssh-add ~/.ssh/id_rsa).- Enabled port tunneling with ‘
AllowTcpForwarding yes‘.
gpg
- Generated keys are stored in
~/.gnupg.
Printing
- Ghostscript translates PostScript into forms that can be understood by your printer.
- The print queue is managed by the Common Unix Printing System (CUPS).
- Users can submit print jobs using
lpr. - Typically a print queue is located in
/var/spool/cups. lpq -ato display all pending print jobs on local and remote printers.
- qmail and Postfix are modular servers.
newaliasescommand converts the aliases file to a binary format.
logs
logrotatecan be used to manage the size of log files.loggeris the command used to record to the system log.- Start syslogd with the
-roption to enable acceptance of remote machine logs.
bash
/etc/profileis the global configuration file for the bash
shell.
Network Addresses
- IP addresses can be broken into a network address and a computer address based on a netmask / subnet mask.
- Network address is a block of IP addresses that are used by one physical network.
- Computer address identifies a particular computer within that network.
- IPv4 addresses.
- 32 bits (4 bytes), binary.
- Represented as four groups of decimal numbers separated by dots
(ex.192.168.1.1). - Classes are address ranges determined by a binary value of the leftmost digit.
00000001 - 01111111=1 - 127— Class A10000000 - 10111111=128 - 191— Class B11000000 - 11011111=192 - 223— Class C11100000 - 11101111=224 - 239— Class D11110000 - 11110111=240 - 255— Class E- If it starts with a
0= Class A,1= Class B,11= Class C,111= Class D,1111= Class E
- Reserved private address spaces / RFC 1918 addresses are:
- Class A —
10.0.0.0 - 10.255.255.255 - Class B —
172.16.0.0 - 172.31.255.255 - Class C —
192.168.0.0 - 192.168.255.255
- Class A —
- Network Address Translation (NAT) routers can substitute their own IP address on outgoing packets from machines within a reserved private address space; effectively allowing any number of computers to hide behind a single IP address.
- Address Resolution Protocol (ARP) can be used to convert between MAC and IPv4 addresses.
- IPv6 addresses.
- 128 bits (16 byte), hexadecimal.
- Represented as eight groups of 4-digit hexadecimal values separated by colons
(ex.2001:4860:4860:0000:0000:0000:0000:8888). - Two types of network addresses:
- Link-Local
- Nonroutable — can only be used for local network connectivity.
fe80:0000:0000:0000:is the standard for IPv6 interfaces.
- Global
- Uses a network address advertised by a router on the local network.
- Link-Local
- Neighbor Discovery Protocol (NDP) can be used to convert between MAC and IPv6 addresses.
- Netmasks / subnet masks are binary numbers that identify which portion of an IP address is a network address and which part is a computer address.
1= part of the network address.0= part of the computer address.- They can be represented using dotted quad notation or Classless Inter-Domain Routing (CIDR) notation:
- Dotted Quad:
255.255.255.0255=11111111— all eight bits are the network address.0=00000000— all eight bits belong to a computer address.
- CIDR:
192.168.1.1/24- The number after the forward slash represents the number of bits belonging to the network address.
- To convert from
192.168.1.100/27CIDR to dotted quad netmask:27represents the number of bits with a value of1, starting from the left-most digit:11111111 11111111 11111111 11100000
- Convert the binary values of each byte to decimal values:
11111111= 128+64+32+16+8+4+2+1 =25511100000= 128+64+32 =224
- Put all of the decimal values in a dotted quad format:
255.255.255.224
- To convert from
255.255.192.0dotted quad to CIDR:- Convert the decimal values to binary values:
255=11111111192=11000000- Math Tip
- Take
255and subtract192to get63. - Since
63is 1 less than64, all bits below the 64th are1
(i.e.001111111). - Subtract
11111111(binary 255) by this value00111111, to get11000000.
- Take
- Math Tip
0=00000000
- Place the binary values into one 32 bit string:
11111111 11111111 11000000 00000000
- Count the number of digits from the left with a value of
1:18- So the IP would be represented as
xxx.xxx.xxx.xxx/18in CIDR notation.
- Convert the decimal values to binary values:
- Dotted Quad:
- Media Access Control (MAC) addresses represent unique hardware addresses.
- 48 bits (6 bytes), hexadecimal.
- A broadcast query is sent out to all computers on a local network and asks a machine with a given IP address to identify itself. If the machine is on the network it will respond with its hardware address, so the TCP/IP stack can direct traffic for that IP to the machine’s hardware address.
- Dynamic Host Configuration Protocol (DHCP).
ipandifconfigcan both be used to add a new IPv6 address to a network interface.ifconfig promiscconfigures the interface to run in promiscuous mode — receiving all packets from the network regardless of the packet’s intended destination.
Network Configuring
ifconfig
route
/etc/nsswitch.conf
Network Diagnostics
netstat
host
dig
netcat / nc
nmap
tracepath
traceroute / traceroute6
ping / ping6
/etc/services
- Provides a human-friendly mapping between internet services, their ports, and protocol types.
- Each line describes one service:
service-name port/protocol [aliases ...]
Ports & Services
- SNMP listens on port 162 by default.
User and Group Files
/etc/passwd
- Contains information about users, their IDs, and basic settings like home directory and default shell.
- One line for each user account, with seven fields separated by colons.
- Username
- Password
xmeans the password is encrypted in the /etc/shadow file.
- UID
- GID
- Comment
- the user’s real name is generally stored here
- Home directory
- Default shell
- Examples:
root:x:0:0:root:/root:/bin/bashjeff:x:1000:1000:jeff,,,:/home/jeff:/bin/bash
/etc/shadow
- Contains encrypted passwords and information related to password/account expirations.
- One line for each user account, with nine fields separated by colons.
- Username
- Encrypted password
*means the account does not accept logins.!means the account has been locked from logging in with a password.!!means the password hasn’t been set yet.
- Last day the password changed (in days since January 1st, 1970).
- Min number of days to wait before a password change is allowed.
- Max number of days a password is valid for before a change is required.
- Password expiration occurs after this date.
- An expired password means the user must change their password to gain access again.
- Number of days to start showing warnings before the max date is reached.
- Number of inactive days allowed after password expiration.
- Account deactivation occurs after the inactive day is passed.
- A deactivated account requires a system admin to reinstate the account.
- Day when account expiration will occur (in days since January 1st, 1970).
- Reserved field that hasn’t been used for anything.
- Examples:
jeff:$9$eNcrYpt3D.23534e/ghlar2k.:17706:0:99999:7:::sshd:*:17706:0:99999:7:::
/etc/group
- Contains information about groups, their ID, and their members.
- One line per group, with four fields separated by colons.
- Group name
- Password
xmeans the password is encrypted in the/etc/gshadowfile.
- GID
- User list (comma separated)
- Examples:
jeff:x:1000:sambashare:x:126:jeff
User & Group Commands
- The first 100 UID and GIDs are reserved for system use.
0typically corresponds toroot.
- The first normal user account is usually assigned a UID of
500or1000. - User and group numbering limits are set in the
/etc/login.defsfile.UID_MINandUID_MAXdefines the minimum and maximum UID value for an ordinary user.GID_MINandGID_MAXwork similarly for groups.
chage
- chage can set the password expiration information for a user.
-llists current account aging details.-d/--lastdaysets the day that the password was last changed
(without actually changing the password).- Accepts a single number (representing the number of days since Jan 1st, 1970) or a value formatted in
YYYY-MM-DD. 0will force the user to change their password on the next login.
- Accepts a single number (representing the number of days since Jan 1st, 1970) or a value formatted in
-m/--mindayssets the number of days that must pass before a password can be changed.0disables any waiting period.
-M/--maxdayssets the number of days before a password change is required.- Accepts a single value for the number of days.
-1disables checking for password validity.
-W/--warndayssets when to start to displaying a warning message that a required password change is coming.-I/--inactivesets the number of days a password must be expired for the password to be marked inactive.- Accepts a single number.
-1removes an account’s inactivity.
-E/--expiredatesets the account expiration date.- Accepts a single number or
YYYY-MM-DDvalue. -1removes the expiration date.
- Accepts a single number or
- If no options are provided to
chage, it will interactively prompt for input to the various values it can set.
useradd / adduser (Debian)
- Doesn’t work as intended in Debian based distributions (because they’ve had a bug since forever and would rather you use a completely new command than get on board with standards… /rant), use
adduserinstead. - Creates new users or updates default new user details.
-D/--defaultsuse Default values for anything not explicitly specified in options.- Execute
useradd -Dwithout any other options to display the current defaults.GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/sh
SKEL=/etc/skel
CREATE_MAIL_SPOOL=no
- Execute
-d/--home-dirspecify home directory.-e/--expiredatesets the expiration date of the account.YYYY-MM-DD- Similar to
chage -E
-f/--inactivesets the number of days before making an account inactive after password expires.- Similar to
chage -I
- Similar to
-g/--gidgroup name or number for the user’s initial login group.- The group must already exist.
-G/--groupssupplementary groups to add the user to.- Groups are separated by commas with no white space.
-m/--create-homecreates the user’s home directory if it does not already exist.-M/--no-create-homeexplicitly specifies not to create the home directory for the user.- Overrides the
CREATE_HOME=yesvalue in/etc/login.defs, if set.
- Overrides the
-k/--skelspecifies the skeleton directory to use.- The
-moption must be used for this to work. - Without this option, it defaults to the
SKELvariable value in/etc/default/useradd.
- The
-K/--keysets UID_MIN, UID_MAX, UMASK, etc. KEY=VALUE option in the/etc/login.defsfile.-N/--no-user-groupdo not create a group with the same name as the user, but add the user to the group specified by the-goption.-o/--non-uniqueallow creation of a user account with a duplicate UID- Must use the
-uoption to specify the UID to use.
- Must use the
-p/--passwordthe encrypted password to use, as returned by thecryptcommand.- Not recommended to use due to plaintext password appearing in history.
-r/--systemcreate a reserved system account.- No aging information in /etc/shadow, UID/GID are generated in reserved range.
-s/--shellspecifies the user’s default shell. –- Default value is the SHELL variable in
/etc/default/useradd.
- Default value is the SHELL variable in
-u/--uidspecify the UID.-U/--user-groupexplicitly create a group with the same name as the user.
usermod
userdel
groupadd / addgroup (Debian)
groupmod
groupdel
newgrp
getent
getentdisplays the contents of various Name Service Switch (NSS) libraries.- Supported libraries:
- ahosts
- ahostsv4
- ahostsv6
- aliases
- ethers
- group
- gshadow
- hosts
- initgroups
- netgroup
- networks
- passwd
- protocols
- rpc
- services
- shadow
- Supported libraries:
Sudoers
- Access to the
sudocommand is configured in the/etc/sudoersfile. visudois the recommended command to edit the/etc/sudoersfile — as it locks the file from other’s editing it at the same time.- Syntax for entries in the sudoers file:
username hostname = TAG: /command1, /command2, [...]- Example:
ray rushmore = NOPASSWD: /bin/kill, /bin/ls, /usr/bin/lprm
- Tags:
PASSWD/NOPASSWD— require or not require the user to enter their password to usesudo.EXEC/NOEXEC— allow or prevent executables from running further commands itself.- Example, shell escapes will be unavailable in
viwithNOEXEC.
- Example, shell escapes will be unavailable in
FOLLOW/NOFOLLOW— allow or prevent opening a symbolic link file.MAIL/NOMAIL— whether or not mail is sent when a user runs a command.SETENV/NOSETENV— use the values ofsetenvor not on a per-command basis.
- Use of the
sudocommand is logged via syslog by default.
Preface
Generally it is recommended to forward X using SSH, as it provides an encrypted connection. However, on machines limited to a local network, tunneling through SSH results in a performance hit.
This article covers how to forward X without using SSH on Ubuntu 18.04.
Local machine = the machine you have access to and want to do work on.
Remote machine = the machine that will be running the applications.
Steps
- Enable X Server to listen via TCP on the local machine.
sudo vim /etc/X11/xinit/xserverrc- Change:
exec /usr/bin/X -nolisten tcp "$@" - To:
exec /usr/bin/X "$@"
- Change:
sudo vim /etc/gdm3/custom.conf- Add
Enable=trueunder the[xmdcp]section. - Add
DisallowTCP=falseunder[security]section.
- Add
- Restart X on the local machine.
- There are several ways to accomplish this, here are a couple of easy ones:
sudo reboot- Switch to a text mode and back to graphical mode:
sudo systemctl isolate multi-user.targetsudo systemctl isolate graphical.target
- There are several ways to accomplish this, here are a couple of easy ones:
- Add local hostname to hosts file on the remote machine.
sudo vim /etc/hosts- Add:
ip_address hostname [aliases]
- Add:
- Add remote hostname to authorized xhosts on local machine.
xhost +hostname
- Export the DISPLAY environment variable on the remote machine to that of the local machine.
export DISPLAY=hostname:0.0
- Launch an X application via SSH or telnet when connected to the remote machine, and it should open on the local machine.
Example Screenshot
Configuring Hardware
Exam Objectives
- 101.1 – Determine and configure hardware settings
- 102.1 – Design hard disk layout
- 104.1 – Create partitions and filesystems
- 104.2 – Maintain the integrity of filesystems
- 104.3 – Control mounting and unmounting of filesystems
Configuring the Firmware and Core Hardware
Firmware is the lowest level software that runs on a computer. A computer’s firmware begins the boot process and configures certain hardware devices.
Key components managed by the firmware (and Linux, once it’s booted) include interrupts, I/O addresses, DMA addresses, the real-time clock, and Advanced Technology Attachment (ATA) hard disk interfaces.
Understanding the Role of the Firmware
Many types of firmware are installed on the various hardware devices found inside a computer, but the most important firmware is on the motherboard.
In the past, most x86 and x86_64 based computers had a firmware known as the Basic Input/Output System (BIOS). Since 2011, however, Extensible Firmware Interface (EFI) and it’s successor, Unified EFI (UEFI), has become the standard.
Note: While most x86 and x86_64 computers use a BIOS or EFI, some computers may use other software in place of these types of firmware. For example, old PowerPC-based Apple computers use OpenFirmware.
Despite the fact that EFI isn’t a BIOS, most manufacturers refer to it by that name in their documentation. Additionally, the the exam objectives refer to the BIOS, but not EFI.
The motherboard’s firmware resides in electronically erasable programmable read-only memory (EEPROM), aka flash memory.
When a computer is turned on, the firmware performs a power-on self-test (POST), initializes hardware to a known operational state, and loads the boot loader from the boot device (typically the first hard disk), and passes control onto the boot loader — which in turn loads the operating system.
Most BIOSs and EFIs provide an interactive interface to configure them — typically found by pressing the Delete key or a Function key during the boot sequence.
Note: Many computers prevent booting if a keyboard is unplugged. To disable this, look for a firmware option called Halt On or similar with the BIOS or EFI.
Once Linux boots, it uses its own drivers to access the computer’s hardware.
Note: Although the Linux kernel uses the BIOS to collect information about the hardware of a machine, once Linux is running, it doesn’t use BIOS services for I/O. As of the 3.5.0 kernel, Linux takes advantages of a few EFI features.
IRQs
An interrupt request (IRQ), or interrupt, is a signal sent to the CPU instructing it to suspend its current activity and handle some external event, such as keyboard input.
On the x86 platform, 16 IRQs are available — numbered 0 to 15. Newer systems, including x86_64 systems, have an even greater number of IRQs.
IRQs and their common uses:
| Command | Typical Use | Notes |
0 |
System Timer | Reserved for internal use. |
1 |
Keyboard | Reserved for keyboard use only. |
2 |
Cascade for IRQs 8 — 15 |
The original x86 IRQ-handling circuit can manage just 8 IRQs; two sets of these are tied together to handle 16 IRQs, but IRQ 2 must be used to handle IRQs 8 — 15 |
3 |
Second RS-232 serial port ( COM2: in Windows) |
May also be shared by a fourth RS-232 serial port. |
4 |
First RS-232 serial port ( COM1: in Windows) |
May also be shared by a third RS-232 serial port. |
5 |
Sound card or second parallel port ( LPT2: in Windows) |
|
6 |
Floppy disk controller | Reserved for the first floppy disk controller. |
7 |
First parallel port ( LPT1: in Windows) |
|
8 |
Real-time clock | Reserved for system clock use only. |
9 |
ACPI system control interrupt | Used by Intel chipsets for the Advanced Configuration and Power Interface (ACPI) used for power management. |
10 |
Open interrupt | |
11 |
Open interrupt | |
12 |
PS/2 mouse | |
13 |
Math coprocessor | Reserved for internal use. |
14 |
Primary ATA controller | The controller for ATA devices such as hard drives; traditionally /dev/hda and /dev/hdb under Linux. |
15 |
Secondary ATA controller | The controller for additional ATA devices; traditionally /dev/hdc and /dev/hdd under Linux. |
Note: Most modern distributions treat Serial ATA disks as SCSI disks, which changes their device identifiers from /dev/hdx to /dev/sdx.
The original Industry Standard Architecture (ISA) bus design (which has become rare on computers since 2001) makes sharing an interrupt between two devices tricky. Therefore, it is ideal that every ISA device should have it’s own IRQ.
The more recent Peripheral Component Interconnect (PCI) bus makes sharing interrupts a bit easier, so PCI devices frequently end up sharing an IRQ.
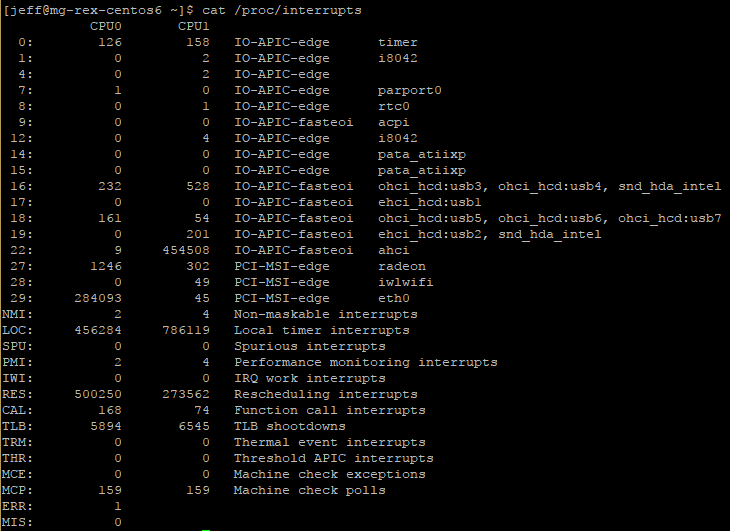
Once a Linux system is running, you can explore what IRQs are being used for various purposes by examining the contents of the /proc/interrupts file:
$ cat /proc/interrupts
Example from CentOS 6.9:
Note: The /proc filesystem is a virtual filesystem — it refers to kernel data that’s convenient to represent using a filesystem, rather than actual files on a hard disk.
The above example output shows the IRQ number in the first column. The next two columns show each CPU core and the number of interrupts each has received for that particular IRQ. The column after them reports the type of interrupt, followed by the name of the device that is located at that IRQ.
Note: The /proc/interrupts file lists IRQs that are in use by Linux, but Linux doesn’t begin using an IRQ until the relevant driver is loaded. This may not happen until you attempt to use the hardware. As such, the /proc/interrupts list may not show all of the interrupts that are configured on your system.
Although IRQ conflicts are rare on modern hardware, they still do occasionally happen. When this occurs, you must reconfigure one or more devices to use different IRQs.
I/O Addresses
I/O addresses (aka I/O ports) are unique locations in memory that are reserved for communications between the CPU and specific physical hardware devices.
Like IRQs, I/O addresses are commonly associated with specific devices, and they should not ordinarily be shared.
Common Linux devices, along with their typical IRQ number and I/O addresses:
| Linux Device | Typical IRQ | I/O Address | Windows Name |
/dev/ttyS0 |
4 |
0x03f8 |
COM1 |
/dev/ttyS1 |
3 |
0x02f8 |
COM2 |
/dev/ttyS2 |
4 |
0x03e8 |
COM3 |
/dev/ttyS3 |
3 |
0x02e8 |
COM4 |
/dev/lp0 |
7 |
0x0378 - 0x037f |
LPT1 |
/dev/lp1 |
5 |
0x0278 - 0x027f |
LPT2 |
/dev/fd0 |
6 |
0x03f0 - 0x03f7 |
A: |
/dev/fd1 |
6 |
0x0370 - 0x0377 |
B: |
Note: Although the use is deprecated, older systems sometimes use /dev/cuax (where x is a number 0 or greater) to indicate an RS-232 serial device. Thus, /dev/ttyS0 and /dev/cua0 refer to the same physical device.
Once a Linux system is running, you can explore what I/O addresses the computer is using by examining the contents of the /proc/ioports file:
$ cat /proc/ioports
jeff@mg-rex-mint ~ $ cat /proc/ioports
0000-0cf7 : PCI Bus 0000:00
0000-001f : dma1
0020-0021 : pic1
0040-0043 : timer0
0050-0053 : timer1
0060-0060 : keyboard
0061-0061 : PNP0800:00
0064-0064 : keyboard
0070-0071 : rtc0
0080-008f : dma page reg
[...truncated...]
DMA Addresses
Direct memory addressing (DMA) is an alternative method of communication to I/O ports. Rather than have the CPU mediate the transfer of data between a device and memory, DMA permits the device to transfer data directly, without the CPU’s attention.
To learn what DMA channels your system uses:
$ cat /proc/dma
jeff@mg-rex-mint ~ $ cat /proc/dma
4: cascade
The above output indicates that DMA channel 4 is in use. As with IRQs and I/O ports, DMA addresses should not be shared normally.
Boot Disks and Geometry Settings
BIOS
The BIOS boot process begins with the computer reading a boot sector (typically the first sector) from a disk and then executing the code contained within it.
This limits boot options for BIOS-based computers to only selecting the order in which various boot devices (hard disks, optical disks, USB devices, network boot, etc.) are examined for a boot sector.
EFI
Under EFI, the boot process involves the computer reading a boot loader file from a filesystem on a special partition, known as the EFI System Partition (ESP). This file can take a special default name or it can be registered in the computer’s NVRAM.
This allows EFI computers to have an extended range of boot options, involving both default boot loader files from various devices and multiple boot loaders on the computer’s hard disks.
Note: Many EFI implementations support a BIOS compatibility mode, and so they can boot media intended for BIOS-based computers.
Booting Options
Some viruses are transmitted by BIOS boot sectors. As such, it’s a good idea not to make booting from removable media the first priority; it’s better to make the first hard disk (or boot loader on a hard disk’s ESP, in the case of EFI) the only boot device.
Note: The Windows A: floppy disk is /dev/fd0 under Linux.
In most cases, the firmware detects and configures hard disks and CD/DVD drives correctly. In rare circumstances, you must tell a BIOS-based computer about the hard disk’s cylinder / head / sector (CHS) geometry.
Cylinder / Head / Sector (CHS) Geometry
The CHS geometry is a holdover from the early days of the x86 architecture. A traditional hard disk layout consist of a fixed number of read/write heads that can move across the disk surfaces / platters. As the disk spins, each head marks out a circular track on its platter. These tracks collectively make up a cylinder. Each track is broken down into a series of sectors.
Any sector on a hard disk can be uniquely identified by three numbers: a cylinder number, a head number, and a sector number.
The x86 BIOS was designed to use the three number CHS identification code — requiring the BIOS to know how many cylinders, heads, and sectors the disk has. Most modern hard disks relay this information to the BIOS automatically, but for compatibility with the earliest hard disks, BIOSs still enable you to set these values manually.
Note: The BIOS will detect only certain types of disks. Of particular importance, SCIS disks and SATA disks won’t appear in the main BIOS disk-detection screen. These disks are handled by supplementary firmware associated with the controllers for these devices. Some BIOSs do provide explicit options to add SCSI devices into the boot sequence, which allows you to give priority to either ATA or SCSI devices. For BIOSs without these options, SCSI disks are generally given less priority than ATA disks.
The CHS geometry presented to the BIOS of a hard disks is a convenient lie — as most modern disks squeeze more sectors onto the outer tracks than the inner ones for greater storage capacity.
Plain CHS geometry also tops out at 504 MiB, due to the limits on the numbers in the BIOS and in the ATA hard disk interface.
Note: Hard drive sizes use the more accurate mebibyte (MiB) size instead of the standard megabyte (MB). In general use, most people will say megabyte when actually referencing the size of a mebibyte (likewise for gigabyte and gibibyte). It’s 1000 MB to 1 GB, whereas it’s 1024 MiB to 1 GiB.
Various patches, such as CHS geometry translation, can be used to expand the limit to about 8 GiB. However, the preference these days is to use logical/linear block addressing (LBA) mode.
In LBA mode, a single unique number is assigned to each sector on the disk, and the disk’s firmware is smart enough to read from the correct head and cylinder when given this sector number.
Modern BIOSs typically provide an option to use LBA mode, CHS translation mode, or possibly some other modes with large disks. EFI uses LBA mode exclusively, and doesn’t use CHS addressing at all (except for BIOS compatibility mode).
Coldplug and Hotplug Devices
Hotplug devices can be attached and detached when the computer is turned on (i.e. “hot”). Coldplug devices must be attached and detached when the computer is in an off state (i.e. “cold”).
Note: Attempting to attach or detach a coldplug device when the computer is running can damage the device or the computer.
Traditionally, components that are internal to the computer, such as CPU, memory, PCI cards, and hard disks, have been coldplug devices. A hotplug variant of PCI does exist, but it’s mainly on servers and other systems that can’t afford downtime required to install or remove a device. Hotplug SATA devices are also available.
Modern external devices, such as Ethernet, USB, and IEEE-1394 devices, are hotplug. These devices rely on specialized Linux software to detect the changes to the system as they’re attached and detached. Several utilities help with managing hotplug devices:
Sysfs
The sysfs virtual filesystem, mounted at /sys, exports information about devices so that user-space utilities can access the information.
Note: A user space program is one that runs as an ordinary program, whether it runs as an ordinary user or as root. This contrasts with kernel space code, which runs as part of the kernel. Typically only the kernel (and hence kernel-space code) can communicate directly with hardware. User-space programs are ultimately the users of hardware, though. Traditionally the /dev filesystem has provided the main means of interface between user space programs and hardware.
HAL Daemon
The Hardware Abstraction Layer (HAL) Daemon, or hald, is a user-space program that runs at all times and provides other user-space programs with information about available hardware.
D-Bus
The Desktop Bus (D-Bus) daemon provides a further abstraction of hardware information access. D-Bus enables processes to communicate with each other as well as to register to be notified of events, both by other processes and by hardware (such as the availability of a new USB device).
udev
Traditionally, Linux has created device nodes as conventional files in the /dev directory tree. The existence of hotplug devices and various other issues, however, have motivated the creation of udev — a virtual filesystem, mounted at /dev, which creates dynamic device files as drivers are loaded and unloaded.
udev can be configured through files located at /etc/udev, but the standard configuration is usually sufficient for common hardware.
Older external devices, such as parallel and RS-232 ports, are officially coldplug in nature. When RS-232 or parallel port devices are hotplugged, they typically aren’t registered by tools such as udev and hald. The OS handles the ports to which these devices connect; so it’s up to user space programs, such as terminal programs and/or the printing system, to know how to communicate with the external devices.
Configuring Expansion Cards
Many hardware devices require configuration — the IRQ, I/O port, and DMA addresses used by the device must be set. In the past, such things were set using physical jumpers. Presently, most devices can be configured via software.
Configuring PCI Cards
The PCI bus, which is the standard expansion bus for most internal devices, was designed with Plug-and-Play (PnP) style configuration in mind, thus automatic configuration of PCI devices is the rule rather than the exception.
In general, PCI devices configure themselves automatically, and there is no need to make any changes. However, it is possible to tweak how PCI devices are detected in several ways:
- The Linux kernel has several options that affect how it detects PCI devices. These can be found in the kernel configuration screens under Bus Options. Most users can rely on the options in their distributions’ default kernel to work properly; but if the kernel was recompiled by yourself, and you are experiencing problems with device detection, these options may need to be adjusted.
- Most firmware implementations have PCI options that change the way PCI resources are allocated. Adjusting these options may help if strange hardware problems occur with PCI devices.
- Some Linux drivers support options that cause them to configure the relevant hardware to use particular resources. Details of these options can often be found in the drivers’ documentation files. These options must be passed to the kernel using a boot loader or kernel module options.
- The
setpciutility can be used to query and adjust PCI devices’ configurations directly. This tool can be useful if you know enough about the hardware to fine-tune its low-level configuration; but it’s not often used to tweak the hardware’s basic IRQ, I/O port, or DMA options.
To check how PCI devices are currently configured, the lspci command can be used to display all of the information about the PCI busses on your system and all of the devices connect to those busses.
Common lspci options:
| Option | Description |
-v |
Increases verbosity of output. This option can be doubled ( -vv) or tripled (-vvv) to produce even more output. |
-n |
Displays information in numeric codes rather than translating the codes to manufacturer and device names. |
-nn |
Displays both the manufacturer and devices names along with their associated numer codes. |
-x |
Displays the PCI configuration space for each device as a hexadecimal dump. This is an extremely advanced option. Tripling ( -xxx) or quadrupling (-xxxx) this option displays information about more devices. |
-b |
Shows IRQ numbers and other data as seen by devices rather than as seen by the kernel. |
-t |
Displays a tree view, depicting the relationship between devices. |
-s [[[[domain]:]bus]:][slot][.[func]] |
Displays only devices that match the listed specification. This can be used to trim the results of the output. |
-d [vendor]:[device] |
Shows data on the specified device. |
-i <file> |
Uses the specified file to map vendor and device IDs to names. (The default is /usr/share/misc/pci.ids). |
-m |
Dumps data in a machine-readable form intended for use by scripts. A single -m uses a backward-compatible format, whereas doubling (-mm) uses a newer format. |
-D |
Displays PCI domain numbers. These numbers normally aren’t displayed. |
-M |
Performs a scan in bus-mapping mode, which can reveal devices hidden behind a misconfigured PCI bridge. This is an advanced option that can be used only by root. |
--version |
Displays version information. |
Learning about Kernel Modules
Kernel drivers, many of which come in the form of kernel modules, handle hardware in Linux.
Kernel modules are stand-alone driver files, typically stored in the /lib/modules directory tree, that can be loaded to provide access to hardware and unloaded to disable such access. Typically, Linux loads the modules it needs when it boots, but you may need to load additional modules yourself.
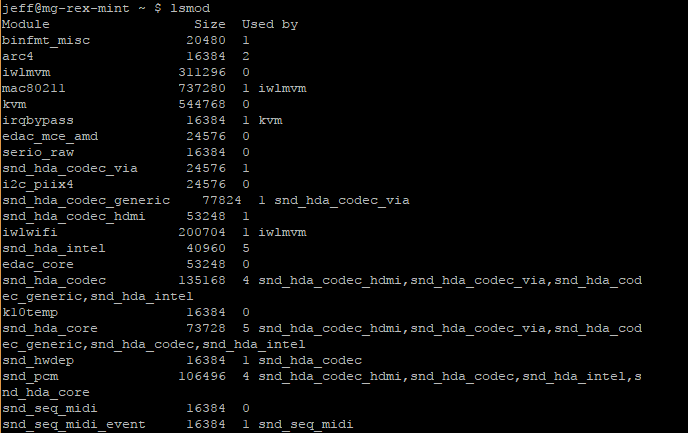
The lsmod command can be used to display the modules that are currently loaded:
$ lsmod
Example output:
[...truncated...]
The above output has several columns:
- The first column is labeled
moduleand represents the name of module currently loaded. To learn more about these modules, use themodinfocommand. - The
Sizecolumn shows how much memory is consumed by the module. - The
Used Bycolumn has a number to represent how many other modules or processes are using that module, followed by a list of those modules/processes. If the number is0it is not currently in use.
Note: The lsmod command displays information only about kernel modules, not about drivers that are compiled directly into the Linux kernel. For this reason, a module may need to be loaded on one system but not on another to use the same hardware, because the second system may compile the relevant driver directly into the kernel.
To find out more details about a particular module, use the modinfo command:
$ modinfo <module-name>
Loading Kernel Modules
Linux enables you to load kernel modules with two programs:
insmodmodprobe
The insmod program inserts a single module into the kernel. This process requires that all dependencies for this module be loaded beforehand.
The modprobe program accomplishes the same actions, but loads the dependencies automatically.
Note: In practice, you may not need to use insmod or modprobe to load modules because Linux can load them automatically. This ability relies on the kernel’s module autoloader feature, which must be compiled into the kernel, and on various configuration files, which are also required for modprobe and some other tools. Using insmod and modprobe can be useful for testing new modules or for working around problems with the autoloader, though.
The insmod command accepts a module filename:
# insmod /lib/modules/3.0.19/kernel/drivers/bluetooth/bluetooth.ko
The modprobe command accepts a module name instead of a filename:
# modprobe bluetooth
Note: modprobe relies on a configuration file at /etc/modprobe.conf or multiple configuration files within /etc/modprobe.d/ to use module names instead of filenames.
There are several options/features for modprobe:
| Feature | Option | Description |
| Be Verbose |
|
Tells modprobe to display extra information about its operations.Typically, this includes a summary of every insmod operation it performs. |
| Change Configuration Files | -C <filename> |
Change the configuration file or directory. |
| Perform a Dry Run | -n--dry-run |
Causes modprobe to perform checks and all other operations except the actual module insertions.This option can be used in conjunction with -v to see what modprobe would do without actually loading the module. |
| Remove Modules | -r--remove |
Reverses modprobe‘s usual effect. It removes the module and any on which it depends (unless those dependencies are in use by other modules). |
| Force Loading | -f--force |
Force the module loading, even if the kernel version doesn’t match what the module expects. This can occassionally be required when using third-party binary-only modules. |
| Show Dependencies | --show-depends |
Shows all modules on which a specific module depends (i.e. module dependencies). Note: This option doesn’t install any of the modules, it only provides information. |
| Show Available Modules | -l--list |
Displays a list of available options whose names match the wildcard specified. For example: Note: If no wildcard is provided, all available modules are displayed. Additionally, this option does not actually install any modules. |
Consult man modprobe for additional options.
Viewing Loaded Module Options
A loaded module has its options/parameters available at:
/sys/module/<module-name>/parameters/<parameter-name>
Removing Kernel Modules
In most cases, modules can be loaded indefinitely; the only harm that a module does when it’s loaded but not used is consume a small amount of memory.
Reasons for removing a loaded module can include: reclaiming a tiny amount of memory, unloading an old module so that an updated replacement can be loaded, and removing a module that is suspected to be unreliable.
The rmmod command can be used to unload a kernel module by name:
# rmmod bluetooth
There are several options/features for rmmod:
| Feature | Option | Description |
| Be Verbose |
|
Causes rmmod to display extra information about its operations. |
| Force Removal | -f--force |
Forces module removal, even if the module is marked as being in use. This option has no effect unless the CONFIG_MODULE_FORCE_UNLOAD kernel option is enabled. |
| Wait Until Unused | -w--wait |
Causes rmmod to wait for the module to become unused. Once the module is no longer being used, rmmod unloads the module.Note: rmmod doesn’t return anything until it unloads a module, which can make it look like it’s not doing anything. |
Consult man rmmod for additional options.
Like insmod, rmmod operates on a single module. If an attempt is made to unload a module that’s in use or depended on by other modules, an error message will be displayed. If other modules depend on the module, rmmod lists those modules — making it easier to decide whether to unload them or not.
To unload an entire module stack (a module and all of its dependencies) use the modprobe command with it’s -r option.
Configuring USB Devices
USB Basics
USB is a protocol and hardware port for transferring data to and from devices. It allows for many more (and varied) devices per interface port than either ATA or SCSI, and it gives better speed than RS-232 serial and parallel ports.
- The USB 1.0 and 1.1 specification allow for up to 127 devices and 12Mbps of data transfer.
- USB 2.0 allows for up to 480Mbps of data transfer.
- USB 3.0 supports a theoretical maximum speed of 4.8Gbps, although 3.2Gbps is more likely its top speed in practice. In addition, it also uses a different physical connector than 1.0, 1.1, and 2.0 connectors. USB 3.0 connectors can accept 2.0, 1.1, and 1.0 devices however.
Note: Data transfer speeds may be expressed in bits per second (bps) or multiples thereof, such as megabits per second (Mbps) or gigabits per second (Gbps). Or they can be expressed in bytes per second (Bps) or multiples thereof, such as megabytes per second (MBps). In most cases, there are 8 bits per bytes, so multiplying or dividing by 8 may be necessary to compare devices using different measurements.
Most computers ship with several USB ports. Each port can handle one device itself, but a USB hub can also be used to connect several devices to each port.
Linux USB Drivers
Several different USB controllers are available, with names such as UHCI, OHCI, EHCI, and R8A66597.
Modern Linux distributions ship with the drivers for the common USB controllers enabled, so the USB ports should be activated automatically when the computer is booted.
The UHCI and OHCI controllers handle USB 1.x devices, but most other controllers can handle USB 2.0 devices. A kernel of 2.6.31 or greater is required to use USB 3.0 hardware.
Note: These basic USB controllers merely provide a means to access the actual USB hardware and address the devices in a low-level manner. Additional software (either drivers or specialized software packages) will be needed to make practical use of the devices.
The lsusb utility can be used to learn more about USB devices:
$ lsusb
Example output:
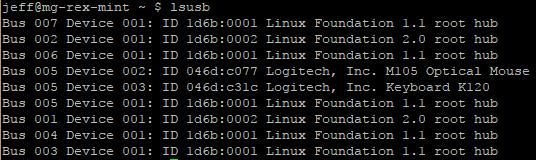
The above output shows seven USB busses are detected (001 – 007). Only the fifth bus (005) shows devices attached — a Logitech mouse and keyboard. These devices have a vendor ID of 046d and product IDs of c007 and c31c, respectively.
Note: The IDs for each device can be used to look up what device they are. This is especially helpful if they have a vague description.
There are several options for lsusb:
| Feature | Option | Description |
| Be Verbose |
|
Produces extended information about each device. |
| Restrict Bus and Device Number | -s [[bus]:][devnum] |
Restricts the output to the specified bus and device number. |
| Restrict Vendor and Product | -d [vendor]:[product] |
Limits the output to a particular vendor and product.vendor and product are the codes just after the ID on each line of the basic output. |
| Display Device by Filename | -D <filename> |
Displays information about the device that’s accessible via <filename>, which should be a file in the /proc/bus/usb directory tree.This directory provides a low-level interface to USB devices. |
| Tree View | -t |
Displays the device list as a tree. This makes it easier to see which devices are connected to which controllers. |
| Version | -V--version |
Displays the version of the lsusb utility. |
Note: Early Linux USB implementations required separate drivers for every USB device. Many of these drivers remain in the kernel, and some software relies on them. For instance, USB disk storage devices use USB storage drivers that interface with Linux’s SCSI support, making USB hard disks, removable disks, and so on look like SCSI devices.
Linux provides a USB filesystem that in turn provides access to USB devices in a generic manner. This filesystem appears as part of the /proc virtual filesystem.
In particular, USB device information is accessible from /proc/bus/usb. Subdirectories of /proc/bus/usb are given numbered names based on the USB controllers instead of the computer, as in /proc/bus/usb/001 for the first USB controller.
USB Manager Applications
USB can be challenging for OSs because it was designed as a hot-pluggable technology. The Linux kernel wasn’t originally designed with this sort of activity in mind, so the kernel relies on external utilities to help manage matters. Two tools in particular are used for managing USB devices: usbmgr and hotplug.
Note: While these tools are not commonly installed by default in Linux distributions, they can come in handy when working with USB devices.
The usbmgr package (located at http://freecode.com/projects/usbmgr) is a program that runs in the background to detect changes on the USB bus. When it detects changes, it loads or unloads the kernel modules that are required to handle the devices. This package uses configuration files in /etc/usbmgr to handle specific devices and uses /etc/usbmgr/usbmgr.conf to control the overall configuration.
With a shift from in-kernel device-specific USB drivers to the USB device filesystem (/proc/bus/usb), usbmgr has been declining in importance.
Instead of usbmgr, most distributions rely on the Hotplug package (http://linux-hotplug.sourceforge.net), which relies on kernel support added with the 2.4.x kernel series.
The Hotplug system uses files stored in /etc/hotplug to control the configuration of specific USB devices. In particular, /etc/hotplug/usb.usermap contains a database of USB device IDs and pointers to scripts in /etc/hotplug/usb that run when devices are plugged in or unplugged. These scripts might change permissions on USB device files so that ordinary users can access USB hardware, run commands to detect new USB disk devices, or otherwise prepare the system for a new (or newly removed) USB device.
Configuring Hard Disks
Three different hard disk interfaces are common on modern computers:
- Parallel Advanced Technology Attachment (PATA), aka ATA
- Serial Advanced Technology Attachment (SATA)
- Small Computer System Interface (SCSI)
In addition, external USB and IEEE-1394 drives are available, as are external variant of SATA and SCSI drives. Each has its own method of low-level configuration.
Configuring PATA Disks
As the name implies, PATA disks use a parallel interface, meaning that several bits of data are transferred over the cable at once. Because of this, PATA cables are wide — supporting a total of either 40 or 80 lines, depending on the variety of PATA.
PATA cables allow for up to two devices to be connected to a motherboard or plug-in PATA controller.
PATA disks must be configured as either a master or slave device. This can be done via jumpers on the disks themselves. Typically, the master device sits at the end of the cable, and the slave device resides on the middle connector. However, all modern PATA disks also support an option called cable select. When set to this option, the drive attempts to configure itself automatically based on its position on the PATA cable.
For best performance, disks should be placed on separate controllers rather than configured as a master and slave on a single controller, because each PATA controller has a limited throughput that may be exceeded by two drives.
In Linux, PATA disks have traditionally been identified as /dev/hda, /dev/hdb, and so on, with /dev/hba being the master drive on the first controller, /dev/hdb being the slave drive on the first controller, etc.
Because of the traditional naming conventions, gaps can occur in the numbering scheme (i.e. if two master drives are on their own controllers, /dev/hda and /dev/hdc will show up but not /dev/hdb).
Partitions are identified by numbers after the main device name, as in /dev/hda1, /dev/hda2, etc.
These disk naming rules also apply to optical media; and most Linux distributions also create a link to the optical drive under the name /dev/cdrom or /dev/dvd.
Note: Most modern Linux distributions favor newer PATA drivers that treat PATA disks as if they were SCSI disks. As such, PATA disks will follow the naming conventions of SCSI disks instead.
Configuring SATA Disks
As the word serial implies, SATA is a serial bus — only one bit of data can be transferred at a time. SATA transfers more bits per unit of time on its data line, making SATA faster than PATA (1.5 – 6.0Gbps for SATA vs. 128 – 1,064Mbps for PATA).
Most Linux SATA drivers treat SATA disks as if they were SCSI disks. Some older drivers treat SATA disks like PATA disks, so they may use PATA names in rare circumstances.
Configuring SCSI Disks
There are many types of SCSI definitions, which use a variety of different cables and operate at various speeds.
SCSI is traditionally a parallel bus, like PATA, but the latest variant, Serial Attached SCSI (SAS), is a serial bus like SATA.
SCSI supports up to 8 or 16 devices per bus, depending on the variety. One of these devices is the SCSI host adapter, which is either built into the motherboard or comes as a plug-in card. In practice, the number of devices that can be attached to a SCSI bus is more restricted because of cable-length limits, which varies from one SCSI variety to another.
Each device has its own SCSI ID number, typically assigned via a jumper on the device. Each device must have its own unique ID.
SCSI IDs are not used to identify the corresponding device file on a Linux system.
- Hard drives follow the naming convention
/dev/sdx(where x is a letter fromaup). - SCSI tapes are named
/dev/stxand/dev/nstx(where x is a number from0up). - SCSI CD-ROMs and DVD-ROMs are named
/dev/scdxor/dev/srx(where x is a number from0up).
SCSI device numbering (or lettering) is usually assigned in increasing order based on the SCSI ID. For example, if one hard disk has a SCSI ID of 2 and another hard disk has a SCSI ID of 4, they will be assigned to /dev/sda and /dev/sdb, respectively.
If a new SCSI disk is added with a lower ID, it will bump up the device letter.
Note: The mapping of Linux device identifiers to SCSI devices depends in part on the design of the SCSI host adapters. Some host adapters result in assignments starting from SCSI ID 7 and work down to 0, with Wide SCSI device numbering starting at ID 14 down through 8.
Another complication is when there are multiple SCSI host adapters on one machine. In this case, Linux assigns device filenames to all of the disks on the first adapter, followed by all of those on the second adapter. Depending on where the drivers for the SCSI host adapters are found (compiled directly into the kernel or loaded as modules) and how they’re loaded (for modular drivers), it may not be possible to control which adapter takes precedence.
Note: Remember that some non-SCSI devices, such as USB disk devices and SATA disks, are mapped onto the Linux SCSI subsystem. This can cause a true SCSI hard disk to be assigned a higher device ID than expected.
The SCSI bus is logically one-dimensional — that is, every device on the bus falls along a single line. This bus must not fork or branch in any way. Each end of the SCSI bus must be terminated. This refers to the presence of a special resistor pack that prevents signals from bouncing back and forth along the SCSI chain. Consult with a SCSI host adapter and SCSI device manual to learn how to properly terminate them.
Configuring External Disks
External disks come in several varieties, the most common of which are USB, IEEE-1394, and SCSI (SCSI has long supported external disks directly, and many SCSI host adapters have both internal and external connectors).
Linux treats external USB and IEEE-1394 disks just like SCSI devices, from a software point of view. Typically, a device can be plugged in, a /dev/sdx device node will appear, and it can be used the same way a SCSI disk can be.
Note: External drives are easily removed, and this can be a great convenience; however, external drives should never be unplugged until they’ve been unmounted in Linux using the umount command.
Designing a Hard Disk Layout
Whether a system uses PATA, SATA, or SCSI disks, a disk layout must be designed for Linux.
Why Partition?
Partitioning provides a variety of advantages, including:
Multiple-OS Support
Partitioning keeps the data for different OSs separate — allowing many OSs to easily coexist on the same hard disk.
Filesystem Choice
Different filesystems — data structures designed to hold all of the files on a partition — can be used on each partition if desired.
Disk Space Management
By partitioning a disk, certain sets of files can be locked into a fixed space. For example, if users are restricted to storing files on one or two partitions, they can fill those partitions without causing problems on other partitions, such as system partitions. This feature can help keep your system from crashing if space runs out.
Disk Error Protection
Disks sometimes develop problems. These problems can be the result of bad hardware or errors that creep into the filesystems. Splitting a disk into partitions provides some protection against such problems.
Security
You can use different security-related mount options on different partitions. For instance, a partition that holds critical systems files might be mounted in read-only mode, preventing users from writing to that partition.
Backup
Some backup tools work best on whole partitions. By keeping partitions small, backups can be made easier than they would be if the partitions were large.
Understanding Partitioning Systems
Partitions are defined by data structures that are written to specified parts of the hard disk.
Several competing systems for defining partitions exist. On x86 and x86_64 hardware, the most common method up until 2010 had been the Master Boot Record (MBR) partitioning system. It was called this because it stores its data in the first sector of the disks, known as the MBR.
The MBR system is limited in the number of partitions it supports, and partition placement cannot exceed 2 tebibytes when using the nearly universal sector size of 512 bytes.
The successor to MBR is the GUID Partitioning Table (GPT) partitioning system, which has much higher limits and certain other advantages.
Note: Still more partitioning systems exist. For instance, Macintoshes that use PowerPC CPUs generally employ the Apple Partitioning MAP (APM), and many Unix variants employ Berkeley Standard Distribution (BSD) disk labels.
MBR Partitions
The original x86 partitioning scheme allowed for only four partitions.
As hard disks increased in size, and the need for more partitions became apparent, this original scheme was extended while retaining backwards compatibility. The new scheme uses three partitioning:
- Primary partitions – which are the same as the original partition types.
- Extended partitions – which are a special type of primary partition that serve as placeholders for logical partitions.
- Logical partitions – which reside within an extended partition.
Because logical partitions reside within a single extended partition, all logical partitions must be contiguous.
The MBR partitioning system uses up to four primary partitions, one of which can be an extended partition that contains logical partitions.
Many OSs, such as Windows, and FreeBSD, must boot from primary partitions. Because of this, most hard disks include at least one primary partition. Linux is not limited like this, and can be booted from a disk containing no primary partitions.
The primary partitions have numbers in the range of 1-4, whereas logical partitions are numbered 5 and up. Gaps can appear in the numbering of MBR primary partitions; however, such gaps cannot exist in the numbering of logical partitions.
In addition to holding the partition table, the MBR data structure holds the primary BIOS boot loader — the first disk-loaded code that the CPU executes when a BIOS-based computer boots.
Because the MBR exists only in the first sector of the disk, it’s vulnerable to damage. Accidental erasure of the MBR will make the disk unusable unless a backup was made previously.
Note: The MBR partitions can be backed up with sfdisk -d /dev/sda > sda-backup.txt. The backup file can then be copied to a removable disk or another computer for safekeeping. To restore a backup: sfdisk -f /dev/sda < sda-backup.txt.
Note2: Another option to backup the MBR is with dd if=/dev/sda of=/root/sda.mbr count=1 bs=512. This uses the dd command to make a full backup of the first 512 bytes. Restoring the MBR would just involve swapping the if and of values (i.e. dd if=/root/sda.mbr of=/dev/sda).
MBR partitions have type codes, which are 1-byte (two-digit hexadecimal) numbers, to help identify their purpose.
Common type codes include:
0x0c(FAT)0x05(old type of extended partition)0x07(NTFS)0x0f(newer type of extended partition)0x82(Linux swap)0x83(Linux filesystem)
GPT Partitions
GPT is part of Intel’s EFI specification, but GPT can be used on computers that don’t use EFI.
GPT employs a protective MBR, which is a legal MBR definition that makes GPT-unaware utilities think that the disks holds a single MBR partition that spans the entire disk. Additional data structures define the true GPT partitions. These data structures are duplicated, with one copy at the start of the disk and another at its end. This provides redundancy that can help in data recovery should an accident damage one of the two sets of data structures.
GPT does away with the primary/extended/logical distinction of MBR. Up to 128 partitions can be defined by default (with the limit able to be raised, if necessary). Gaps can occur in the partition numbering, however, GPT partitions are usually numbered consecutively starting with 1.
GPT’s main drawback is that support for it is relatively immature. The fdisk utility doesn’t work with GPT disks, although alternatives to fdisk are available. Some version of the GRUB boot loader also don’t support it.
Like MBR, GPT supports partition type codes; however, GPT type codes are 16-byte GUID values. Disk partitioning tools typically translate these codes into short descriptions, such as “Linux swap”.
Confusingly, most Linux installations use the same type code for their filesystems that Windows uses for its filesystems, although a Linux-only code is available and gaining popularity among Linux distributions.
An Alternative to Partitions: LVM
An alternative to partitions for some functions is logical volume management (LVM).
To use LVM, one or more partitions are set aside and assigned MBR partition type codes of 0x8e (or an equivalent on GPT disks). Then a series of utilities, such as pvcreate, vgcreate, lvcreate, and lvscan, are used to manage the partitions (known as physical volumes in this scheme). These physical volumes can be merged into volume groups; and logical volumes can also be made within the volume groups. Ultimately these logical volumes are assigned names in the /dev/mapper directory for access, such as /dev/mapper/myvolume-home.
The biggest advantage to LVM is that it grants the ability to resize logical volumes easily, without worrying about the positions or sizes of the surrounding partitions.
It’s easiest to configure a system with at least one filesystem (dedicated to /boot, or perhaps the root filesystem containing /boot) in its own conventional partition, reserving LVM for /home, /usr, and other filesystems.
LVM is most likely to be useful for creating an installation with many specialized filesystems while retaining the option of resizing those filesystems in the future, or if a filesystem larger than any single hard disk is necessary.
Mount Points
Once a disk is partitioned, an OS must have some way to access the data on the partitions.
In Windows, assigning a drive letter, such as C: or D:, to each partition does this (Windows uses partition type codes to decide which partitions get drive letters and which to ignore). Linux doesn’t use drive letters. Instead, Linux uses a unified directory tree.
Each partition is mounted at a mount point in the directory tree.
A mount point is a directory that’s used as a way to access the filesystem on the partition, and mounting the filesystem is the process of linking the filesystem to the mount point.
Partitions are mounted just about anywhere in the Linux directory tree, including in directories on the root partition as well as directories on mounted partitions.
Common Partitions and Filesystem Layouts
Note: The typical sizes for many of the following partitions can vary greatly depending on how the system is used.
Common partitions and their uses:
| Partition (Mount Point) | Typical Size | Use |
| Swap (not mounted) |
1 – 2x the system RAM size | Serves as an adjunct to system RAM. It is slow but enables the computer to run more or larger programs, and allows for hibernation mode from the power menu. |
/home |
200 MiB – 3 TiB (or more) |
Holds user’s data files. Isolating it on a separate partition preserves user data during a system upgrade. Size depends on the number of users and their data storage needs. |
/boot |
100 – 500 MiB |
Holds critical boot files. Creating it as a separate partition lets you circumvent limitations on older BIOSs and boot loaders, which often can’t boot a kernel from a point above a value between 504 MiB and 2 TiB. |
/usr |
500 MiB – 25 GiB |
Holds most Linux program and data files. Changes implemented in 2012 are making it harder to create a separate /usr partition in many distributions. |
/usr/local |
100 MiB – 3 GiB |
Holds Linux program and data files that are unique to this installation, particularly those that you compile yourself. |
/opt |
100 MiB – 5 GiB |
Holds Linux program and data files that are associated with third-party packages, especially commercial ones. |
/var |
100 MiB – 3 TiB (or more) |
Holds miscellaneous files associated with the day-to-day functioning of a computer. These files are often transient in nature. Most often split off as a separate partition when the system functions as a server that uses the /var directory for server-related files like mail queues. |
/tmp |
100 MiB – 20 GiB |
Holds temporary files created by ordinary users. |
/mnt |
N/A | Not a separate partition; rather, it or its subdirectories are used as mount points for removal media like CDs and DVDs. |
/media |
N/A | Holds subdirectories that may be used as mount points for removable media, much like /mnt or its subdirectories. |
Some directories — /etc, /bin, /sbin, /lib, and /dev — should never be placed on separate partitions. These directories host critical system configuration files or files without which a Linux system cannot function. For instance, /etc contains /etc/fstab, the file that specifies what partitions correspond to what directories, and /bin contains the mount utility that’s used to mount partitions on directories.
Note: The 2.4.x and newer kernels include support for a dedicated /dev filesystem, which obviates the need for files in a disk-based /dev directory; so, in some sense, /dev can reside on a separate filesystem, although not a separate partition. The udev utility controls the /dev filesystem in recent version of Linux.
Creating Partitions and Filesystems
Partitioning involves two tasks:
- Creating the partitions.
- Preparing the partitions to be used.
Partitioning a Disk
The traditional Linux tool for MBR disk partitioning is called fdisk. This tool’s name is short for fixed disk.
Although fdisk is the traditional tool, several others exist. One of these in GNU Parted, which can handle several different partition table types, not just the MBR that fdisk can handle.
Note: If you prefer fdisk to GNU Parted, but must use GPT, there is GPT fdisk (http://www.rodsbooks.com/gdisk/). This package’s gdisk program works much like fdisk but on GPT disks.
Using fdisk
To use Linux’s fdisk, type the command name followed by the name of the disk device to be partitioned:
# fdisk /dev/hda
Command (m for help):
At the interactive prompt, there are several options:
| Effect | Option | Description |
| Display the Current Partition Table |
|
Displays the current partition table. |
| Create a Partition | n |
Results in a series of prompts for information about the partition to be created — whether it should be a primary, extended, or logical partition; the partition’s starting cylinder; the partition’s ending cylinder or size; etc. A partition’s size can be specified with a plus sign, number, and suffix (ex. +20G).Note: Failure to align partitions properly can result in severe performance degradation. For more information see: http://www.ibm.com/developerworks/library/l-linux-4kb-sector-disks/index.html |
| Delete a Partition | d |
If more than one partition exists, the program will ask for the partition number to be deleted. |
| Change a Partition’s Type | t |
Prompts for a partition number and type code for a partition.fdisk assigns a type code of 0x83 by default. If a swap partition or some other partition type is desired, this option can be used.Note: Typing L during the prompt will list available partition types. |
| List Partition Types | l |
Lists the most common partition type codes. |
| Mark a Partition Bootable | a |
Sets a bootable flag on the partition. Some OSs, such as Windows, rely on such bootable flags in order to boot. |
| Get Help | m? |
Provides a summary of fdisk commands. |
| Exit | qw |
q exits without saving any changes.w exists after writing the changes to disk. |
Using gdisk
To work with a GPT-formatted hard drive, the gdisk utility will need to be using instead of fdisk.
On the surface, gdisk works nearly identical to fdisk.
To display existing partitions, use the print command:
$ gdisk /dev/sda
Command (? for help): print
Remember that GPT format doesn’t use primary, extended, or logical partitions — all partitions are the same.
The Code column shows the 16-byte GUID value for the GPT partition, indicating the type of partition.
The 8200 code is the proper code for a Linux swap area, and 8300 is the code commonly used for Linux partitions. 0700 is a Windows partition code, which is sometimes used even in Linux distributions instead of 8300.
Using GNU Parted
GNU Parted (http://www.gnu.org/software/parted/) is a partitioning tool that works with MBR, GPT, APM, and BSD disk labels, and other disk types.
Although GNU Parted isn’t covered on the exam, knowing a bit about it can be handy.
To start GNU Parted:
$ parted /dev/sda
At the parted prompt, ? can be entered for a help menu. To display the current partition table use the print command. To create a GPT disk, use the mklabel command. To create a new partition, use the mkpart command.
Note: Some more advanced partition capabilities appear in GUI tools, such as the GNOME Partition Editor (http://gparted.sourceforge.net), aka GParted.
Preparing a Partition for Use
Once a partition is created, it must be prepared for use. This process is often called “making a filesystem” or “formatting a partition”. It involves writing low-level data structures to disk.
Note: The word formatting is somewhat ambiguous. It can refer either to low-level formatting, which creates a structure of sectors and tracks on the disk media, or high-level formatting, which creates a filesystem. Hard disks are low-level formatted at the factory and should never need to be low-level formatted again.
Common Filesystem Types
Ext2fs
The Second Extended File System (ex2fs or ext2) is the traditional Linux-native filesystem.
The ext2 filesystem type code is ext2.
Ext3fs
The Third Extended File System (ext3fs or ext3) is basically ext2fs with a journal added.
The ext3 filesystem type code is ext3.
Ext4fs
The Fourth Extended File System (ext4fs or ext4) adds extensions intended to improve performance, the ability to work with very large disks (over 16 TiB, which is the limit for ext2 and ext3), and the ability to work with very large files (>2 TiB).
The ext4 filesystem type code is ext4.
ReiserFS
A journaling filesystem designed from scratch for Linux. It’s particularly good at handling large numbers of small files because ReiserFS uses various tricks to squeeze the ends of the files into each other’s unused space.
The type code for this filesystem is reiserfs.
JFS
IBM developed the Journaled File System (JFS) for its AIX OS on mainframe systems and later reimplemented it on its attempt at a workstation OS, called OS/2. After the demise of OS/2, the OS/2 version of JFS was subsequently donated to Linux.
The type code for JFS is jfs.
XFS
Silicon Graphics (SGI) created its Extents File System (XFS) for its IRIX OS, and like IBM, later donated the code to Linux.
The type code for XFS is xfs.
Btrfs
Pronounced as “butter eff ess” or “bee tree eff ess”) is an advanced filesystem with features inspired by those of Sun’s Zettabyte File System (ZFS). Like ext4fs, JFS, and XFS, Btrfs is a fast performer, and is able to handle very large disks and files.
In addition to Linux-native filesystems, additional filesystems may need to be dealt with from time to time, including:
FAT
The File Allocation Table (FAT) filesystem is old and primitive — but ubiquitous. Every major OS understands FAT, making it an excellent filesystem for exchanging data on removable disks.
Two major orthogonal variants of FAT exist: they vary in the size of the FAT data structure, after which the filesystem is named (12-, 15- or 32-bit pointers), and have variants that support long filenames. Linux automatically detects the FAT size.
The original FAT filenames are limited to eight characters with an optional three-character extension (8.3 filenames). To use the original FAT filenames, use the Linux filesystem type code of msdos.
To use Windows-style long filenames, use the type code of vfat. A Linux-only long filename system also exists with a type code of umsdos, and supports additional Linux features.
NTFS
The New Technology File System (NTFS) is the preferred filesystem for Windows NT and beyond.
As of the 2.6.x kernel series, Linux can reliably read NTFS and can overwrite existing files, but the Linux kernel can’t write new files to an NTFS partition. There are separate drivers outside of the kernel that can be used in Linux to create new files on an NTFS filesystem — the most popular of which is the NTFS-3G driver.
HFS and HFS+
Apple has long used the Hierarchical File System (HFS) with its Mac Os; and Linux provides full read/write support for HFS.
HFS+ is an extended version of HFS that better supports large hard disks and many Unix-like features.
Linux 2.6.x and newer kernels provide limited HFS+ support, but write support works only with the HFS+ journal disabled.
ISO-9660
The standard filesystem for CD-ROMs has long been ISO-9660.
This filesystem comes in several levels:
- Level 1 – Similar to the original FAT in that it supports only 8.3 filenames.
- Levels 2 & 3 – Adds support for longer 32-character filenames.
Linux supports ISO-9660 using its iso9660 filesystem type code.
Linux’s ISO-9660 support also works with the Rock Ridge extensions, which are a series of extensions to ISO-9660 to enable it to support Unix-style long filenames, permissions, symbolic links, and so on. Similarly, Joliet provides support for long filenames as implement for Windows. If a disc includes Rock Ridge or Joliet extensions, Linux will automatically detect and use them.
UDF
The Universal Disc Format (UDF) is the next-generation filesystem for optical discs. It’s commonly used on DVD-ROMs and recordable optical discs. Linux supports it, but read/write UDF support is still in its infancy.
Note: ISO-9660 and other optical disc filesystems are created with special tools intended for this purpose. Specifically, mkisofs creates an ISO-9660 filesystem (optionally with Rock Ridge, Joliet, HFS, and UDF components added) while cdrecord writes this image to a black CD-R. The growisofs program combines both functions but only works on recordable DVD media.
Creating a Filesystem
Linux filesystem tools have filenames in the form of mkfs.fstype, where fstype is the filesystem type code. These tools can also be called from a front-end tool called mkfs; where the filesystem type code is passed after the -t option:
# mkfs -t ext3 /dev/sda2
Note: For ext2 and ext3 filesystems, the mke2fs program is often used instead of mkfs. The mke2fs program is just another name for mkfs.ext2.
The -c option is supported by several filesystems, and causes the tool to perform a bad-block check — every sector in the partition is checked to be sure it can reliably hold data. If it can’t, the sector is marked as bad and isn’t used.
The -m <percent> option can be used to specify a reserved-space percentage. This leaves additional space for root on the filesystem; preventing ordinary users from completely filling the disk and preventing the creation of new files. The default value is 5% if the -m option is not passed with a value.
Linux distributions also provide tools for various non-Linux filesystems. The most important of these may be for FAT. The main tool for this task is called mkdosfs, but it’s often linked to the mkfs.msdos and mkfs.vfat names as well.
This program can automatically adjust the size of the FAT data structure to 12, 16, or 32 bits depending on the device size. To override this option, the -F <fat-size> option can be used (where <fat-size> is the size in bits — 12, 16, or 32).
No special options are required to create a FAT filesystem that can handle Windows-style (VFAT) long filenames; the OS creates these.
Creating Swap Space
Linux can use a swap partition, which is a partition that Linux treats as an extension of memory; or a swap file, which is a file that works in the same way. Both are examples swap space.
Linux uses the MBR partition type code of 0x82 to identify swap space, but as with other partitions, this code is mostly a convenience to keep other OSs from trying to access Linux swap partitions.
Linux uses /etc/fstab to define which partitions to use as swap space.
Note: Solaris for x86 also uses an MBR partition type code of 0x82 to refer to a Solaris partition. In order to prevent issues when dual-booting between Solaris and Linux, it may be necessary to use Linux’s fdisk to change the partition type codes temporarily to keep Linux from trying to use a Solaris partition as swap space, or to keep Solaris from trying to interpret Linux swap space as a data partition.
In order to prepare swap space, use the mkswap command:
# mkswap /dev/sda3
To use the swap space temporarily, activate it with the swapon command:
# swapon /dev/sda3
To activate swap space permanently, create an entry for it in the /etc/fstab file.
Maintaining Filesystem Health
Filesystems can become “sick” in a variety of ways. They can become overloaded with too much data, they can be tuned inappropriately for the system’s use, or they can become corrupted because of buggy drivers, buggy utilities, or hardware errors.
Note: Many of Linux’s filesystem maintenance tools should be run when the filesystem is not mounted. Changes made by maintenance utilities while the filesystem is mounted can confuse the kernel’s filesystem drivers, resulting in data corruption.
Tuning Filesystems
Filesystems are basically just big data structures — they’re a means of storing data on disk in an indexed method that makes it easy to locate the data at a later time.
Some filesystems include tools that provide options that affect performance. For example, ext2/3/4 provides these tools for tuning their filesystems:dumpe2fs, tune2fs, and debugfs. The first tool provides information about the filesystem, and the other two provide the ability to change tuning options.
Obtaining Filesystem Information
A lot of information about an ext2 or ext3 filesystem can be gathered from the dumpe2fs command:
dumpe2fs [options] <device>
<device> is the filesystem device file, such as /dev/sdb9.
The -h option can be used to omit information about group descriptors (which are useful in very advanced filesystem debugging but not for basic filesystem tuning).
The information displayed from dumpe2fs can be immediately understood but some parts may be puzzling. For example, Inode count is a count of the number of inodes supported by the filesystem. Each inode contains information for one file; and because Linux treats everything as a file (including directories), the inode count is effectively the limit to the number of files, directories, etc. that can be stored on the filesystem.
dumpe2fs can be safely run on a mounted filesystem.
Most other filesystems lack an equivalent to dumpe2fs, but XFS provides a similar application with xfs_info:
# xfs_info /dev/sda5
In addition to using the partition name, xfs_info can accept the mount point as well:
# xfs_info /home
Another XFS tool is xfs_metadump, which copies the filesystem’s metadata (filenames, file sizes, etc.) to a file:
# xfs_metadump /dev/sda5 ~/dumpfile
This dump file is intended for debugging purposes if the filesystem is behaving strangely, and can be sent to XFS developers for study.
Adjusting Tunable Filesystem Parameters
tune2fs can be used to change many of the filesystem parameters reported by dumpe2fs:
tune2fs [options] <device>
There are many options that tune2fs supports:
| Effect | Option | Description |
| Adjust the Maximum Mount Count | -c <num-mounts> |
Ext2fs, ext3fs, and ext4fs require a periodic disk check with fsck. The disk check is designed to prevent errors from creeping onto the disk undetected. This option can be used to change the number of times the disk can be mounted without a disk check.<num-mounts> is the number of mounts. |
| Set the Mount Count | -C <mount-num> |
Sets the number of times the disk has been mounted to |
| Adjust the Time between Checks | -i <interval> |
Periodic disk checks are required based on time as well as the number of mounts. <interval> is a number with the character d, w, or m appended — representing days, weeks, or months, respectively.ex. -i 2w for two weeks. |
| Add a Journal | -j |
Adds a journal to the filesystem (effectively converting ext2 to ext3). |
| Set the Reserved Blocks | -m <percent> |
Sets the percentage of disk space reserved for use by root. The default value is 5%, even when this option is not called explicitly. Note: Reserved space can also be set using a value in blocks with the -r option. |
Note: tune2fs should not be used to adjust a mounted filesystem. To adjust a key mounted filesystem, such as the root (/) filesystem, it may be necessary to boot up an emergency disk system — such as Parted Magic (http://partedmagic.com), or a distributions’ install disc.
In XFS, the xfs_admin command is roughly equivalent to tune2fs. Some of it’s options include:
| Effect | Option | Description |
| Use Version 2 Journal Format | -j |
Enables version 2 log (journal) format, which can improve performance in some situations. |
| Obtain the Filesystem Label and UUID | -l-u |
A filesystem’s label (name) can be acquired with the -l option; and its universally unique identifier (UUID) can be acquired with the -u option.Note: The blkid command can display the label and UUID of any partition’s filesystem, not just an XFS partition. |
| Set the Filesystem Label and UUID | -L <label>-U <uuid> |
Sets a filesystem’s label or UUID. The label is at most 12 characters in length. The word generate can be used for the UUID value to create a new UUID. |
An example of using xfs_admin would be:
# xfs_admin -L game_data /dev/sda5
This would set the name of the filesystem on /dev/sda5 to game_data.
Interactively Debugging a Filesystem
A filesystem’s features can be interactively modified using the debugfs command:
# debugfs /dev/sdb2
debugfs:
There are several subcommands that can be used at this prompt:
At the interactive prompt, there are several options:
| Effect | Subcommand | Description |
| Display Filesystem Superblock Information | show_super_stats |
Produces superblock information, similar to what dumpe2fs displays. |
| Display Inode Information | stat <filename> |
Displays the inode data on a file or directory. |
| Undelete a File | undelete <inode> <name> |
Undeletes a file where <inode> is the inode number of the deleted file and <name> is the filename to recover it as. |
| Extract a File | write <internal-file> <external-file> |
Extracts a file from the filesystem being manipulated to the main Linux system. Note: This subcommand can be useful if a filesystem is badly damaged and a critical file needs to be extracted without mounting the filesystem. |
| Manipulate Files | cd, ln, rm, etc. |
Most shell commands work as subcommands for debugfs. |
| Get Help | list_requestslrhelp? |
Produces a summary of available commands. |
| Exit | quit |
Exits from the program. |
Note: Although debugfs is a useful tool, it’s potentially dangerous. Do not use it on a mounted filesystem, and do not use it unless you must.
Be aware that the exam does cover debugfs. For more information, consult man debugfs.
The closest XFS equivalent for debugfs is xfs_db. However, this tool is only intended for XFS experts to use.
Maintaining a Journal
Ext2fs suffers from a major limitation: after a power failure, a system crash, or another uncontrolled shutdown, the filesystem could be in an inconsistent state. The only way to mount the filesystem safely so that you’re sure its data structures are valid is to perform a full disk check on it.
The solution to this problem is to change to a journaling filesystem. Such a filesystem maintains a journal, which is a data structure that describes pending operations. Prior to writing data to the disk’s main data structures, Linux describes what it’s about to do in the journal. When the operations are complete, their entries are removed from the journal.
In the event of a crash or power failure, the system can examine the journal and check only those structures described within it. If inconsistencies are found, the system can roll back or complete the changes, returning the disk to a consistent state without having to check every data structure in the filesystem.
Five journaling filesystems are common on Linux:
- ext3fs
- ext4fs
- ReiserFS
- XFS
- JFS
A journal can be added to an ext2 filesystem to convert it into an ext3 filesystem (via the -j option on tune2fs.
Note: Although using tune2fs on a mounted filesystem is generally inadvisable, it’s safe to use it’s -j option on a mounted filesystem. The result is a file called .journal that holds the journal. If you add a journal to an unmounted filesystem, the journal file will be invisible.
To use a journal, the filesystem must be mounted with the correct filesystem type code — ext3 rather than ext2 for ext3fs or ext4 for ext4fs.
The journal, like other filesystem features, has its own set of parameters. These can be set with the -J option of tune2fs. In particular, the size=<journal-size> and device=<external-journal> suboptions enable the ability to set the journal’s size and the device on which it’s stored. By default, the system creates a journal that’s the right size for the filesystem, and stores the journal on the filesystem itself.
Checking Filesystems
Bugs, power failures, and mechanical problems can all cause the data structures on a filesystem to become corrupted.
Linux includes tools for verifying a filesystem’s integrity and for correcting any problems that may exist. The main tool for this is fsck. This program is actually a front end to other tools, such as e2fsck (aka fsck.ext2, fsck.ext3, and fsck.ext4) or XFS’s xfs_check and xfs_repair. The syntax for fsck is:
fsck [-sACVRTNP) [-t <fstype>] [--] [<fsck-options>] <filesystems>
Common parameters of fsck:
| Effect | Option | Description |
| Check All Files | -A |
Check all of the filesystems marked to be check in /etc/fstab.This option is normally used in system startup scripts. |
| Indicate Progress | -C |
Displays a text-mode progress indicator of the check progress. Most check programs don’t support this feature, but e2fsck does. |
| Show Verbose Output | -V |
Produces verbose output of the check process. |
| No Action | -N |
Displays what it would normally do without actually doing it (i.e. a dry run). |
| Set the Filesystem Type | -t <fstype> |
Force the type. Used in conjunction with -A, this causes the program to check only the specified filesystem types, even if others are marked to be checked. Note: If <fstype> is prefixed with no, then all filesystems except the specified type are checked. |
| Filesystem-Specific Options | -- -a-- -p-- -r-- -f |
Filesystem check programs for specific filesystems often have their own options. The double dash (--) option passes these options to the underlying check program.-a or -p performs an automatic check.-r performs an interactive check.-f forces a full filesystem check even if the filesystem initially appeared to be clean. |
Note: Run fsck only on filesystems that are not currently mounted or that are mounted in read-only mode. Changes written to disk during normal read/write operations can confuse fsck and result in filesystem corruption.
Linux runs fsck automatically at startup on partitions that are marked for this in /etc/fstab.
The normal behavior of e2fsck causes it to perform just a quick cursory examination of a partition if it’s been unmounted cleanly. However, e2fsck forces a check if the disk has gone longer than a certain amount of time without checks (normally six months) or if the filesystem has been mounted more than a certain number of times since the last check (normally 20). These options can be changed using tune2fs.
Journaling filesystems do away with full filesystem checks at system startup even if the system wasn’t shut down correctly. However, if odd behavior is encountered with a journaling filesystem, it is recommended to unmount it and perform a filesystem check.
Some Linux distributions do odd things with some journaling filesystem check programs. For instance, Mandriva uses a symbolic link from /sbin/fsck.reiserfs to /bin/true. This configuration speeds system boot times should ReiserFS partitions be marked for automatic checks, but can be confusing if you need to check the filesystem manually. If this is the case, run /sbin/reiserfsck to do the job. Similarly, /sbin/fsck.xfs is usually nothing but a script that advises the user to run xfs_check or xfs_repair.
Monitoring Disk Use
The df and du programs can summarize disk use on a partition-by-partition and directory-by-directory basis, respectively.
Monitoring Disk Use by Partition
df [options] [files]
Without any options or files passed to df, it will provide a summary of disk space used on all of a system’s partitions.
Several options exist for df:
| Effect | Option | Description |
| Include All Filesystems | -a--all |
Includes pseudo-filesystems with a size of 0 in the output. Such filesystems include /proc, /sys, /proc/bus/usb, etc. |
| Use Scaled Units (Power 2) |
-h--human-readable |
Scale and label units in kibibytes (KiB), mebibytes (MiB), gibibytes (GiB), etc. |
| Use Scaled Units (Power 10) |
-H--si |
Scale and label units in kilobytes (KB), megabytes, (MB), gigabytes (GB), etc. Note: -k/--kilobytes and -m/--megabytes options also output in their respective units. |
| Summarize Inodes | -i--inodes |
By default, df summarizes used and available disk space. This option changes the output to used and available inodes. Note: This option works well on ext2, ext3, ext4, XFS, and some other filesystems with a fixed number of inodes when the filesystem is created. Other filesystems, such as ReiserFS and Btrfs, create inodes dynamically and render this option meaningless. |
| Local Filesystems Only | -l--local |
Omit network filesystems. |
| Display Filesystem Type | -T--print-type |
Adds filesystem type to the information displayed. |
| Limit by Filesystem Type | -t <fstype>--type=<fstype>
|
Displays information about filesystems of a specified type, or excludes filesystems of a specified type, from the report. |
Monitoring Disk Use by Directory
du [options] [directories]
This command searches specified directories and reports how much disk space each is consuming. This search is recursive, so it will display the information for the desired directory and all of its subdirectories.
Several options exist for du:
| Effect | Option | Description |
| Summarize Files and Directories | -a--all |
By default, du reports on the space used by the files in directories but not the space used by individual files. This option causes du to output that information. |
| Compute a Grand Total | -c--total |
Adds a grand total to the end of the output. |
| Use Scaled Units (Power 2) |
-h--human-readable |
Scale and label units in kibibytes (KiB), mebibytes (MiB), gibibytes (GiB), etc. |
| Use Scaled Units (Power 10) |
-H--si |
Scale and label units in kilobytes (KB), megabytes, (MB), gigabytes (GB), etc. Note: -k/--kilobytes and -m/--megabytes options also output in their respective units. |
| Count Hard Links | -l--count-links |
Normally, du counts files that appear multiple times as hard links only once. This reflects true disk space used, but sometimes it may be desireable to count each link independently. This option does just that. |
| Limit Depth | --max-depth=<num> |
Limits the report to <num> levels.Note: The subdirectories’ contents are counted even if they aren’t reported. |
| Summarize | -s--summarize |
Limits the report to the files and directories specified on the command line. Note: This is equivalent to --max-depth=0. |
| Limit to One Filesystem | -x--one-file-system |
Limits the report to the current filesystem. If another filesystem is mounted within the same tree being summarized, its contents are not included in the report. |
Mounting and Unmounting Filesystems
Filesystems are most often used by being mounted — that is, associated with a directory.
Mounting a filesystem can be accomplished on a one-time basis by using the mount tool (and then unmounted with the umount tool). Or a filesystem can be mounted persistently across reboots by editing the /etc/fstab file.
Temporarily Mounting or Unmounting Filesystems
Syntax and Parameters for mount
mount [-alrsvw] [-t <fstype>] [-o <options>] [<device>] [<mountpoint>]
Common parameters of mount:
| Effect | Parameter | Description |
| Mount All Filesystems | -a |
Mount all filesystems listed in /etc/fstab. |
| Mount Read-Only | -r |
Mount the filesystem in read-only mode. |
| Show Verbose Output | -v |
Produce verbose output to provide comments on operations as they occur. |
| Mount Read/Write | -w |
Attempt to mount the filesystem for both read and write operations. This is the default option for most filesystems. Note: -o rw has the same effect. |
| Specify the Filesystem Type | -t <fstype> |
Specifies the type of the filesystem by type code:
If this parameter is omitted, Linux will attempt to auto-detect the filesystem type. |
| Mount by Label or UUID | -L <label>-U <uuid> |
Mounts the filesystem with the specified label or UUID, respectively. |
| Additional Filesystem Options | -o <options> |
Passes additional filesystem specific options. |
Ordinarily, only root may issue a mount command; however, if /etc/fstab specifies the user, users, or owner option, an ordinary user may mount a filesystem using a simplified syntax in which only the device or mount point is specified, but not both. For example, a user may type mount /mnt/cdrom to mount a CD-ROM if /etc/fstab specifies /mnt/cdrom as its mount point and uses the user, users, or owner option.
Note: Most Linux distributions ship with auto-mounter support, which causes the OS to mount removable media automatically when they’re inserted. To eject the disk, the user will need to unmount the filesystem using the umount command.
When Linux mounts a filesystem, it ordinarily records this fact in /etc/mtab.
The /etc/mtab file has a format similar to that of /etc/fstab and is stored in /etc, but it’s not a configuration file that should be edited.
Options for mount
Important filesystem options for the mount command:
| Option | Supported Filesystems | Description |
defaults |
All | Uses the default options for the filesystem. This is used primarily in the /etc/fstab file to ensure that a value for an options column is provided. |
loop |
All | Allows the mounting of a file as if it were a disk partition. Ex. mount -t vfat -o loop image.img /mnt/image mounts the file as if it were a disk. |
autonoauto |
All | Sets whether or not the filesystem is mounted at boot time or when root issues the mount -a command.The default is auto, but noauto is appropriate for removable media. This is used in /etc/fstab. |
usernouser |
All |
Sets whether or not ordinary users can mount the filesystem. |
users |
All | Similar to user, except any user may unmount the filesystem once it has been mounted. |
owner |
All | Similar to user, except the user must own the device file.Note: Some distributions, such as Red Hat, assign ownership of some device files (such as /dev/fd0 for the floppy disk) to the console user, making this a helpful option. |
remount |
All | Changes one or more mount options without explicitly unmounting a partition. Often used to enable or disable write access to a partition. |
ro |
All | Specifies a read-only mount of the filesystem. The default option for filesystems without write support (or bad write support). |
rw |
All read/write filesystems | Specifies a read/write mount of the filesystem. The default option for filesystems that have write support. |
uid=<value> |
Most filesystems that do not support Unix-style permissions (ex. vfat, hpfs, ntfs, and hfs). |
Sets the owner of all files. Note: Check Linux user IDs in the /etc/passwd file. |
gid=<value> |
Same as above | Sets the group of all files. Note: Check Linux group IDs in the /etc/group file. |
umask=<value> |
Same as above | Sets the umask for the permissions on files.<value> is interpreted in binary as bits to be removed from permissions on files. For example, umask=027 yields permissions of 750 or -rwxr-x---.Note: When used in conjunction with uid=<value> and gid=<value>, this option lets you control who can access files on FAT, HPFS, and other foreign filesystems. |
fmask=<value> |
Same as above | Sets the umask for files only, not directories. |
conv=<code> |
Most filesystems used on Microsoft and Apple (ex. msdos, umsdos, vfat, hpfs, and hfs). |
If
The default value is |
norock |
iso9660 |
Disables Rock Ridge extensions for ISO-9660 CD-ROMs. |
nojoliet |
iso9660 |
Disables Joliet extensions for ISO-9660 CD-ROMs. |
Documentation for options that are supported by various filesystems may appear in /usr/src/linux/Documentation/filesystems or /usr/src/linux/fs/<fsname>, where <fsname> is the name of the filesystem.
Using umount
umount [-afnrv] [-t <fstype>] [<device> | <mountpoint>]
Common parameters of umount:
| Effect | Parameter | Description |
| Unmount All | -a |
Attempts to unmount all of the partitions listed in /etc/mtab. |
| Force Unmount | -f |
Force an unmount operation that might otherwise fail. |
| Fall Back to Read-Only | -r |
Remount as read-only mode if the filesystem cannot be unmounted. |
| Unmount Filesystem by Type | -t <fstype> |
Unmount only partitions matching the specified filesystem type code. |
As with mount, normal users can not ordinarily use umount. The exception to this is if the partition or device is listed in /etc/fstab and specifies the user, users, or owner option.
Note: Be cautious when unplugging USB disk-like devices. Linux caches accesses to most filesystems, which means that data may not be written to the disk until some time after a write command. Because of this, it is possible to corrupt a disk by ejecting or unplugging it, even when the drive isn’t active. Always issue a umount command before ejecting a mounted disk. Another way to write the cache to disk is to use the sync command, but because this command does not fully unmount a filesystem, it is not a substitute for umount.
Permanently Mounting Filesystems
The /etc/fstab file consists of a series of lines that contain six fields each; the fields are separated by one or more spaces or tabs. A line that begins with a hash mark (#) is a comment and is ignored.
The meaning of each field is as follows:
Device
These are usually device filenames that reference hard disks, USB drives, etc. Most distributions now specify partitions by their labels or UUIDs:
LABEL=/home
UUID=1234abcde-123a-5432-9876-5678fde123b2
It is also possible to be a network drive or a share on Windows or a Samba server:
server:/home
//winsrv/shr
Mount Point
This is where the partition or disk will be mounted in the unified Linux filesystem.
This should usually be an empty directory in another filesystem, but the root filesystem (/) and swap space (swap) are exceptions.
Filesystem Type
The type code of the filesystem
A type code of auto lets the kernel auto-detect the filesystem type.
Mount Options
Most filesystems support several mount options, which modify how the kernel treats the filesystem.
Multiple options may be specified in a comma separated value (CSV) list. For example:
uid=500,umask=0
Ordinarily, most SMB/CIFS shares require a username and password as a means of access control. Although the username=<name> and password=<pass> options can be used for smbfs or cifs, these options are undesirable, particularly in /etc/fstab, because anyone can read this file to see the password. A better alternative is to use the credentials=<file> option, which points to a file that holds the username and password, such as:
username=jeff
password=DontHackMeBro
Backup Operation
Contains a 1 if the dump utility should back up a partition, and 0 if it should not.
If the dump backup program is never used, this option is essentially meaningless.
Filesystem Check Order
At boot, Linux suse the fsck program to check filesystem integrity. The final column specifies the order in which this check occurs. A 0 means that fsck should not check a filesystem.
The root partition should have a value of 1, and all others should be 2.
Some filesystems, like ReiserFS, shouldn’t be checked.
Hardware and Hard Disk Configuration Essentials
- Summarize BIOS and EFI essentials:
- The BIOS and EFI provide two important functions: they configure the hardware built into the motherboard and the hardware on many types of plug-in cards, and they begin the computer’s boot process — passing control on to the boot loader in the MBR or EFI partition of GPT-formatted disks.
- The BIOS is being retired in favor of EFI.
- Describe what files contain important hardware information:
- There are many files under the
/procfilesystem. Familiarize yourself with:/proc/ioports,/proc/interrupts,/proc/dma,/proc/bus/usb, and others.
- There are many files under the
- Explain Linux’s model for managing USB hardware:
- Linux uses drivers for USB controllers. These drivers in turn are used by some device-specific drivers and by programs that access USB hardware via entries in the
/proc/bus/usbdirectory tree.
- Linux uses drivers for USB controllers. These drivers in turn are used by some device-specific drivers and by programs that access USB hardware via entries in the
- Summarize how to obtain information about PCI and USB devices:
- The
lspciandlsusbprograms return information about PCI and USB devices, respectively. Various manufacturers and their products’ configuration options can be learned by using these commands.
- The
- Identify common disk types and their features:
- PATA disks were the most common type on PCs until about 2005. Since then, SATA disks, have gained substantial popularity.
- SCSI disks have long been considered the top-tier disks, but their high price has kept them out of inexpensive commodity PCs.
- Describe the purpose of disk partitions:
- Disk partitions break the disk into a handful of distinct parts. Each partition can be used by a different OS, can contain a different filesystem, and is isolated from other partitions. These features improve security and safety and can greatly simplify running a multi-OS system.
- Summarize important Linux disk partitions:
- The most important Linux disk partition is the root (
/) partition, which is at the base of the Linux directory tree. - Other important partitions include a swap partition,
/homefor home directories,/usrfor program files,/varfor transient system files,/tmpfor temporary user files,/bootfor the kernel and other critical boot files, etc.
- The most important Linux disk partition is the root (
- Describe commands that help you monitor disk use:
- The
dfcommand provides a one-line summary of each mounted filesystem’s size, available space, free space, and percentage of space used. - The
ducommand adds up the disk space used by all of the files in a specified directory tree and presents a summary by directory and subdirectory.
- The
- Summarize the tools that can help keep a filesystem healthy:
- The
fsckprogram is a front end to filesystem-specific tools suche2fsckandfsck.jfs. By whatever name, these programs examine a filesystem’s major data structures for internal consistency and can correct minor errors.
- The
- Explain how filesystems are mounted in Linux:
- The
mountcommand ties a filesystem to a Linux directory; once the filesystem is mounted, its files can be accessed as part of the mount directory. - The
/etc/fstabfile describes permanent mappings of filesystems to mount points; when the system boots, it automatically mounts the described filesystems unless they use thenoautooption (which is common for removable disks).
- The
Package Managers, Libraries, and Processes
Exam Objectives
- 102.3 – Manage shared libraries
- 102.4 – Use Debian package management
- 102.5 – Use RPM and Yum package management
- 103.5 – Create, monitor, and kill processes
- 103.6 – Modify process execution priorities
Package Managers
Two major package management tools exist for Linux:
- RPM Package Manager (RPM)
- Debian package manager
Their package files, file databases, and details of operation differ — making them incompatible with one another.
Package Concepts
Any one program may rely on several other programs or libraries to operate, and these other programs or libraries may also rely on even more programs or libraries as well.
The Linux kernel is the foundation that all programs rely on.
Linux package management tools help to keep track of installed software, and help to install or upgrade new software.
Packages
Packages are collections of files which can be installed on a computer.
Typically a package is a single file that expands to many more files upon installation.
Each package contains additional information about itself that is useful for package management systems.
Installed File Database
Package systems maintain a database of installed files.
The database includes information about every file installed via the package system, the name of the package to which each of those files belongs, and associated additional information.
Dependencies
Packaging systems also maintain dependency information — a list of requirements packages have for each other.
Checksums
Package systems maintain checksums and assorted ancillary information about files; which is used to verify the validity of installed software.
These checksums are intended to help spot:
- Disk errors
- Accidental overwriting of files
- Other non-sinister problems
Note: Because intruders could install altered software through a package system, checksums are of limited use for detecting intrusions.
Upgrades and Uninstallation
By tracking files and dependencies, package systems can easily upgrade or uninstall packages.
Binary Package Creation
The RPM and Debian package systems both provide tools to help create binary packages from source code.
This has advantages over compiling software from source, because you can use a package management system to track dependencies, attend to individual files, etc.
Note: If the developers of a package didn’t provide explicit support for a peculiar CPU you are using, this feature can be used to install software on it.
Using RPM
The most popular package manager for Linux is the RPM Package Manager (RPM).
RPM Distributions
Red Hat developed RPM for its own distribution, but released the software under the General Public License (GPL) so that others are free to use it in their own Linux distributions.
Red Hat is largely comprised of three distributions:
- Fedora – The testbed for new developments.
- Red Hat Enterprise Linux (RHEL) – The for-pay enterprise distribution with support.
- CentOS (Community Enterprise OS) – The free version of RHEL essentially.
Mandriva (formerly Mandrake) and Yellow Dog are based on Red Hat, so they use RPMs.
SUSE uses RPMs as well, but is not as similar to Red Hat.
RPM Conventions
RPM supports any CPU architecture.
For the most part, source RPMs are transportable across architectures — the same source RPM can be used to build packages for x86, AMD64, PowerPC, ARM, SPARC, etc.
Some programs are composed of architecture-independent scripts and need no recompilation to run on other CPUs.
The naming convention for RPM packages is as follows:
packagename-a.b.c-x.arch.rpm
packagename is the name of the package.
a.b.c is the version number. It’s not required to be three numbers separated by dots, but that’s the most common form.
x is the build number / release number. This number represents minor changes made by the package maintainer, not by the program author. These changes may represent altered startup scripts or configuration files, changed file locations, added documentation, or patches appended to the original program to fix bugs or to make the program more compatible with the target Linux distribution.
arch is a code for the package’s architecture. The i386 architecture code represents a file compiled for any x86 CPU from 80386 onward. Pentium and newer may use i586 or i686. PowerPC uses ppc. x86-64 platforms use x86_64. Scripts, documentation, and other CPU-independent packages generally use the noarch architecture code.
Note: The information in the filename of an RPM package is retained within the package. This can be helpfulif you must rename an RPM package and need to know it’s original filename details.
Compatibility
Compatibility issues between RPM packages and certain RPM distributions can crop up from time to time for the following reasons:
- Distributions may use different versions of the RPM utilities.
- An RPM package designed for one distribution may have dependencies that are unmet in another distribution.
- An RPM package may be built to depend on a package of a particular name (such as samba-client depending on samba-common) and the distribution in use has named the package differently (ex. samba-com). Note: This objection can be overridden by using the
--nodepsswitch but the package may not work once installed. - Even when a dependency appears to be met, different distributions may include slightly different files in their packages.
RPM meta-packagers, such as the “Yellow Dog Updater, Modified” (YUM), can simplify locating and installing packages designed for your distribution.
The rpm Command Set
The main RPM utility program:
rpm [operation] [options] [package-files|package-names]
Common rpm operations:
| Operation | Description |
-i |
Installs a package. Note: System must not contain a package of the same name. |
-U |
Installs a new package or upgrades an existing one. |
-F |
Upgrades a packages only if an earlier version already exists. |
-q |
Queries a package — finds whether a package is installed, what files it contains, etc. |
-V |
Verifies a package — checks that its files are present and unchanged since installation. |
-e |
Uninstalls a package. |
-b |
Builds a binary package, given source code and configuration files. Note: Moved to the rpmbuild command as of RPM version 4.2. |
--rebuild |
Builds a binary package, given a source RPM file. Note: Moved to the rpmbuild command as of RPM version 4.2. |
--rebuilddb |
Rebuilds the RPM database to fix errors. |
Common rpm options:
| Option | Compatible w/ Operations | Description |
--root <dir> |
any |
Modifies the Linux system with a root directory at <dir>. |
--force |
-i, -U, -F |
Forces installation of a package even when it means overwriting existing files or packages. |
-h--hash |
-i, -U, -F |
Displays hash marks (#) to indicate progress of the operation. |
-v |
-i, -U, -F |
Used in conjunction with -h to produce a uniform number of hash marks for each package. |
--nodeps |
|
Prevents dependency checks. |
--test |
|
Checks for dependencies, conflicts, and other problems without installing the package. |
--prefix <path> |
-i, -U, -F |
Sets the installation directory to <path>. |
-a--all |
-q, -V |
Queries or verifies all packages. |
-f <file>--file <file> |
-q, -V |
Queries or verifies the package that owns <file>. |
-p <package-file> |
-q |
Queries the uninstalled RPM <package-file>. |
-i |
-q |
Displays package information, including the package maintainer, a short description, etc. |
-R--requires |
-q |
Displays the packages and files on which this package depends. |
-l--list |
-q |
Lists the files contained in the package. |
The rpm command can be used with one or more packages, separated by spaces.
Installing multiple packages with a single command is recommended — as it ensure dependent packages are installed first.
Some operations require a filename, while others require a package name:
-i, -U, -F, and therebuildoperations require package filenames.-q, -V,and-erequire a package name.-pcan be used to modify-qto use a package filename.
Using the -U operation is recommended — as it enables the installation of a package without having to manually uninstall the old one first:
# rpm -Uvh samba-4.1.9-4.fc20.x86_64.rpm
The -qi operations can be combined to verify that a package is installed; and displays information such as when and where the binary package was built.
Extracting Data from RPMs
RPM files are actually modified cpio archives.
The rpm2cpio program can be used to convert .rpm files to .cpio files:
$ rpm2cpio samba-4.1.9-4.fc20.src.rpm > samba-4.1.9-4.fc20.src.cpio
The cpio program can be used to extract .cpio archived files:
$ cpio -i --make-directories < samba-4.1.9-4.fc20.src.cpio
Note: The -i option is for extraction, and the --make-directories option is used to create directories.
An alternative option is to pipe the two commands together without creating an intermediary file:
$ rpm2cpio samba-4.1.9-4.fc20.src.rpm | cpio -i --make-directories
When extracting binary packages, the output is likely to be a series of subdirectories that mimic the layout of the Linux root directory (i.e. /, /etc, /usr, etc.).
When extracting a source package, the output is likely to be a source code tarball, a .spec file (which holds information that RPM uses to build the package), and some patch files.
Another option for extracting data from RPMs is alien. It can convert an RPM into a Debian package or a tarball.
Using Yum
Yum is one of several meta-packagers — which allows the installation of packages and its dependencies easily using a single command line:
yum [options] [command] [package...]
Yum does this by searching repositories — Internet sites that host RPM files for a particular distribution.
Yum originated from the Yellow Dog Linux distribution, and was later adopted by Red Hat distributions (RHEL, CentOS, Fedora, etc.) and other RPM-based distributions.
Note: Not all RPM-based distributions use Yum. SUSE and Mandriva both use their own meta-packager. Debian-based distributions typically use the Advanced Package Tools (APT).
Common yum commands:
| Command | Description |
| install | Installs one or more packages by package name, and also installs dependencies of the specified packages. |
| update | Updates the specified packages to the latest version. If no packages are specified, yum updates every installed package. |
check-update |
Checks to see if any updates are available. If they are, yum displays their names, versions, and repository area (ex. updates or extras). |
| upgrade | Works like update with the --obsoletes flag set. |
| remove erase |
Deletes a package from the system; similar to rpm -e, but yum also removes depended-on packages. |
| list | Displays information about a package, such as the installed version and whether an update is available. |
| provides whatprovides |
Displays information about packages that provide a specified program or feature. |
| search | Searches package names, summaries, packagers, and descriptions for a specified keyword. |
| info | Displays information about a package, similar to rpm -qi. |
clean |
Cleans up the Yum cache directory. Running this command from time to time is advisable, lest downloaded packages chew up too much disk space. |
shell |
Enters the Yum shell mode, which allows multiple Yum commands to be entered one after another. |
resolvedep |
Displays packages matching the specified dependency. |
localinstall |
Installs the specified local RPM files, using your Yum repositories to resolve dependencies. |
localupdate |
Updates the system using the specified local RPM files, using your Yum repositories to resolve dependencies. |
deplist |
Displays dependencies of the specified package. |
Yum is only as good as its repositories, and cannot install software that’s not stored in those repositories.
To download a package without installing it, the yumdownloader command can be used.
GUI frontends do exist for Yum, such as yumex and kyum.
RPM and Yum Configuration Files
The main RPM configuration file is /usr/lib/rpm/rpmrc.
This file should not be edited directly, instead a /etc/rpmrc (to make global changes) or a ~/.rpmrc (to make per-user changes) file should be created.
These files set a variety of options, mostly related to the CPU optimizations used when compiling source packages. For example, to optimize code for a particular CPU model, the appropriate compiler options can be provided with the optflags line:
optflags: athlon -O2 -g -march=i686
Note: The previous line tells RPM to pass the -O2 -g -march-i686 options to the compiler whenever it’s building for the athlon platform.
Most default rmprc files include a series of buildarchtranslate lines that cause rpmbuild (or rpm for older version of RPM) to use one set of optimizations for a whole family of CPUs. For x86 systems, these lines typically look like:
buildarchtranslate: athlon: i386
buildarchtranslate: i686: i386
buildarchtranslate: i586: i386
buildarchtranslate: i486: i386
buildarchtranslate: i386: i386
These lines tell RPM to translate the athlon, i686, i568, i486, and i386 CPU codes to use the i386 optimizations. This effectively defeats the purpose of any CPU-specific optimizations created on the optflags line, but it guarantees that the RPMs built will be maximally portable. To change this, the line for CPU type must be altered (which can be found with uname -p). For example, to prevent this on an Athlon-based system, enter the following line:
buildarchtranslate: athlon: athlon
The previous line will give a slight performance boost on Athlon systems, but at the cost of reducing portability.
Yum is configured via the /etc/yum.conf file, with additional configuration files in the /etc/yum.repos.d/ directory.
The yum.conf file holds basic options, such as the directory where Yum downloads RPMs and where Yum stores its logs.
The /etc/yum.repos.d/ directory can hold several files, each of which describes a Yum repository.
New repositories can be downloaded as RPMs that can be installed via the rpm command.
Several popular Yum repositories exist:
| Name | Description |
| Livna | Hosts multimedia tools, such as additional codes and video drivers. http://rpm.livna.org/ |
| KDE Red Hat | Contains improved KDE RPMs for those that favor KDE over GNOME (GNU Network Object Model Environment). http://kde-redhat.sourceforge.net/ |
| Fresh RPMs | Provides additional RPMs focused on multimedia applications and drivers. http://freshrpms.net/ |
Note: Many additional Yum repositories exist. A web search for “yum repository” will reveal many other repositories.
RPM Compared to Other Package Formats
When compared to Debian packages, the greatest strength of RPMs is their ubiquity. Many software packages are available in RPM form from the developer and/or their distribution maintainers.
RPMs made for one Linux distribution can often be used for another distribution, but sometimes this can lead to a mismatch of conflicting packages.
Note: To find RPMs for a specific program, RPMFind (http://rpmfind.net/) can be extremely helpful. Likewise, Fresh RPMs (http://freshrpms.net/) can be helpfulfor finding RPMs as well.
Using Debian Packages
Debian packages require knowing how to use the dpkg, dselect, and apt-get commands.
Debian Distributions and Conventions
Debian, Ubuntu, Linux Mint, and Xandros use the Debian package manager. As such, most packages that work with Debian will likely work with other Debian-based systems.
Although Debian doesn’t emphasis the use of GUI configuration tools, its derivatives tend to be more GUI-centric, which makes them more appealing to Linux novices.
Like RPM, the Debian package format is neutral with respect to both OS and CPU type.
Attempts to use the Debian package system and software library on top of non-Linux kernels have been largely abandoned, with the exception of kFreeBSD (http://www.debian.org/ports/kfreebsd-gnu/).
The original Debian distribution has been ported to many different CPUs, including x86, x86-64, IA-64, ARM, PowerPC, Alpha, 680x0, MIPS, and SPARC.
Debian packages follow a similar naming convention as RPMs, but packages sometimes omit codes in the filename to specify a package’s architecture, particularly on x86 packages. For example, a filename ending in i386.deb indicates an x86 binary, powerpc.deb is a PowerPC binary, and all.deb indicates a CPU-independent packages (such as documentation or scripts).
There is no code for Debian source packages because they consist of several separate files.
The dpkg Command Set
Debian packages are incompatible with RPM packages, but the principles of their operation are the same.
The dpkg command can be used to install a Debian package:
dpkg [options] [action] [package-files | package-name]
Common dpkg actions:
| Action | Description |
| -i ––install |
Installs a package. |
| ––configure | Reconfigures an installed package: runs the post-installation script to set site-specific options. |
-r |
Removes a package but leaves its configuration files intact. |
| -P ––purge |
Removes a package (including its configuration files). |
| ––get-selections | Displays currently installed packages. |
| -p ––print-avail |
Displays information about an installed package. |
| -I ––info |
Displays information about an uninstalled package file. |
| -l <pattern> ––list <pattern> |
Lists all installed packages whose names match <pattern>. |
| -L ––listfiles |
Lists the files associated with a package. |
-S <pattern> |
Locates packages that own the files specified by <pattern>. |
-C |
Searches for partially installed packages and suggests what to do with them. |
Common dpkg options:
| Option | Compatible w/ Actions | Description |
--root=<dir> |
any |
Modifies the Linux system with a root directory at <dir>. |
-B--auto-deconfigure |
-r |
Disables packages that rely on one that is being removed. |
--force-things |
assorted |
Overrides defaults that would ordinarily cause dpkg to abort. |
--ignore-depends=<package> |
-i, -r |
Ignores dependency information for the specified package. |
--no-act |
-i, -r |
Checks for dependencies, conflicts, and other problems without actually installing or removing the package. |
--recursive |
-i |
Installs all packages that match the package-name wildcard in the specified directory and all subdirectories. |
-G |
-i |
Doesn’t install the package if a newer version of the same package is already installed. |
-E--skip-same-version |
-i |
Doesn’t install the package if the same version of the package is already installed. |
Note: dpkg expects a package name or a package filename depending on the command. For instance, --install / -i and --info / -I both require a package filename, but other commands take the shorter package name. An example of this would be installing a Samba package:
# dpkg -i samba_4.1.6+dfsg-1ubuntu2.1404.3_amd64.deb
Before upgrading a package, the old package may need to be removed first. To do this, use the -r option with dpkg:
# dpkg -r samba
To find information about an installed package, use the -p option:
# dpkg -p samba
Debian-based systems often use a pair of somewhat higher-level utilities (apt-get and dselect) to handle package installation and removal. However, dpkg is often more convenient when you’re manipulating just one or two packages.
Because dpkg can take package filenames as input, it’s the preferred method of installing a package that was downloaded from an unusual source or created by yourself.
Using apt-cache
The APT suite of tools includes a program, apt-cache, that’s intended solely to provide information about the Debian package database (known in Debian terminology as the package cache).
Common features of apt-cache:
| Feature | Description and Subcommands |
| Display Package Information | Using the showpkg subcommand (ex. apt-cache showpkg samba) displays information about the package.Note: The information displayed is different from dpkg‘s informational actions. |
| Display Package Statistics | Passing the stats subcommand (ex. apt-cache stats) reveals how many packages are installed, how many dependencies are recorded, and various other statistics. |
| Find Unmet Dependencies | Using apt-cache unmet may help if a program reports missing libraries or files. This subcommand returns information about unmet dependencies, which may help to track down the source of missing-file problems. |
| Display Dependencies |
The The |
| Local All Packages | The pkgnames subcommand displays the names of all the packages installed on the system.If a second parameter is provided with this subcommand it will display only the packages that begin with the specified string (ex. apt-cache pkgnames sa). |
Several apt-cache subcommands are intended for package maintainers and debugging serious package database problems rather than day-to-day system administration. Consult the man page for apt-cache for more information.
Using apt-get
APT, and it’s apt-get utility, is Debian’s equivalent to Yum on certain RPM-based distributions.
Debian-based systems include a file, /etc/apt/sources.list, that specifies locations where important packages can be obtained.
Note: Do not add a site to /etc/apt/sources.list unless it can be trusted. The apt-get utility does automatic and semi-automatic upgrades. If unreliable or vulnerable programs exist in a network source added to the sources list, your system will become vulnerable after upgrading via apt-get.
Although APT is most strongly associate with Debian systems, a port for RPM-based systems is also available (see: http://apt4rpm.sourceforge.net/).
The apt-get utility works by obtaining information about available packages from the sources listed in /etc/apt/sources.list and uses that information to upgrade or install packages:
apt-get [options] [command] [package-names]
Common apt-get options:
| Option | Compatible w/ Commands | Description |
-d--download-only |
upgrade, dselect-upgrade, install, source |
Downloads package files but doesn’t install them. |
-f--fix-broken |
install,remove |
Attempts to fix a system where dependencies are unsatisfied. |
-m--ignore-missing--fix-missing |
upgrade, dselect-upgrade, install, remove,source |
Ignores all package files that can’t be retrieved (because of network errors, missing files, etc.). |
-q--quiet |
any |
Omits some progress indicator information. May be doubled (for instance -qq) to produce even less progress information. |
-s--simulate |
any |
Performs a simulation of the action without actually modifying, installing, or removing files. |
-y--yes--assume-yes |
any |
Produces a “yes” response to any yes/no prompt during the installation script. |
-b--compile--build |
source |
Compiles a source package after retrieving it. |
--no-upgrade |
install |
Causes apt-get to not upgrade a package if an older version is already installed. |
Common apt-get commands:
| Command | Description |
update |
Obtains updated information about packages available from the installation sources listed in /etc/apt/sources.list. |
upgrade |
Upgrades all installed packages to the newest versions available, based on locally stored information about available packages. |
dselect-upgrade |
Performs any changes in package status (installation, removal, etc.) left undone after running dselect. |
dist-upgrade |
Similar to upgrade but performs “smart” conflict resolution to avoid upgrading a package if doing so would break a dependency. |
install |
Installs a package by package name (not by package filename), obtaining the package from the source that contains the most up-to-date version. |
remove |
Removes a specified package by package name. |
source |
Retrieves the newest available source package file by package filename, using information about available packages and installation archives listed in /etc/apt/sources.list. |
check |
Checks the package database for consistency and broken package installations. |
clean |
Performs housekeeping to help clear out information about retrieved files from the Debian package database.
Note: If |
autoclean |
Similar to clean, but removes information only about packages that can no longer be downloaded. |
In most cases, no options will be used with apt-get, just a single command and possibly one or more package names. For example, keeping the system up-to-date with any new packages:
# apt-get update
# apt-get dist-upgrade
Using dselect, aptitude, and Synaptic
The dselect program is a high-level text-mode package browser that uses the APT archives defined in /etc/apt/sources.list.
aptitude is another text-based Debian package manager; which combines the interactive features of dselect with the command-line options of apt-get.
In interactive mode, aptitude is similar to dselect, but aptitude adds menus accessed by pressing Ctrl+T.
Searching for packages with aptitude can be performed with aptitude search:
$ aptitude search samba
Features of aptitude on command line and interactive mode:
| Feature | Subcommand | Description |
| Update Package Lists | update |
Updates package lists from the APT repositories. |
| Install Software | install <package> |
Installs packages matching <package>.Note: <package> can end with a hyphen to indicate removal instead (ex. aptitude install zsh- would remove zsh). |
| Upgrade Software | full-upgradesafe-upgrade |
Both options upgrade all installed packages, but safe-upgrade is more conservative about removing packages or installing new ones. |
| Search for Packages | search |
Searches the database for packages matching the specified name. The result is a list of packages, one per line, with a summary code for each package’s install status, name, and description. |
| Clean Up the Database | autocleanclean |
autoclean removes already-downloaded packages than are no longer available, and clean removes all downloaded packages. |
| Obtain Help | help |
Displays a list of all options for aptitude. |
A tool that is similar to dselect and aptitude is the GUI X-based program, Synaptic.
Reconfiguring Packages
Debian packages often provide more-extensive initial setup options than their RPM counterparts. Frequently, the install script included in the package asks a handful of questions. These questions help the package system set up a standardized configuration that is customized for the machine.
To revert to initial standard configuration, the dpkg-reconfigure program can be used:
# dpkg-reconfigure samba
The above command will reconfigure the samba package, ask its initial installation questions again, and restart the Samba daemon.
Debian Packages Compared to Other Package Formats
Debian source packages aren’t single files; they are groups of files — the original source tarball, a patch file that’s used to modify the source code (including a file that controls the building of a Debian package), and an optional .dsc file that contains a digital “signature” to help verify the authenticity of the collection.
Debian package tools combine and compile source packages to create a Debian binary package.
Whereas RPM source packages may contain multiple patch files, Debian source packages only support one single patch file.
Because all distributions that use Debian packages have derived from Debian, almost all are more compatible with one another than RPM-based distributions are to each other.
It is generally more difficult to locate Debian packages than RPMs for exotic programs. If no Debian package can be found, alien can be used to convert an RPM to a Debian format.
Debian maintains a good collection of packages at http://www.debian.org/distrib/packages/.
Configuring Debian Package Tools
The main configuration file for dpkg is /etc/dpkg/dpkg.cfg or ~/.dpkg.cfg.
This file contains dpkg options, but without leading dashes. For example, to force dpkg to always do a test run instead of installation a dpkg.cfg file could contain:
no-act
For APT, the main configuration file that is likely to be modified is /etc/apt/sources.list.
Another APT configuration file is /etc/apt/apt.conf, which controls APT and dselect options.
The format to modify the apt.conf file is complex and modeled after the Internet Software Consortium’s (ISC's) Dynamic Host Configuration Protocol (DHCP) and Berkeley Internet Name Domain (BIND) server configuration files. Options are grouped together by open and close curly braces ( {} ):
APT
{
Get
{
Download-Only "true";
};
};
Note: These lines are equivalent to setting the --download-only option permanently.
For more information on the apt.conf file, consult apt.conf‘s man page; and review the sample configuration file at /usr/share/doc/apt/examples/apt.conf.
Debian’s package tools rely on various files in the /var/lib/dpkg directory tree. These files maintain lists of available packages, lists of installed packages, etc. — effectively making it the Debian installed file database. Due to this directory’s importance, careful consideration should be made before modifying its contents; and backing up this directory is recommended when performing system backups.
Converting between Package Formats
When the appropriate package for a distribution is unable to be found there are several options:
- Continue searching for the appropriate package.
- Create a package from a source tarball using standard RPM or Debian tools.
- Convert between package formats with a utility like
alien.
The alien program comes with Debian and a few other distributions, but it can be installed by typing apt-get install alien on APT systems. Alternatively, it can be found on RPMFind or Debian’s package website.
This program can convert between:
- Debian packages
- RPM packages
- Stampede packages
- Tarballs
In order to convert packages, the package management software for each package must be installed (i.e. RPM and Debian package managers must both be installed to convert between RPM and Debian packages).
Note: Although alien requires both RPM and Debian package systems to be installed to convert between these formats, it doesn’t use the database features of these packages unless the --install option is used.
The alien utility doesn’t always convert all dependency information completely and correctly.
When converting from a tarball, alien copies the files directly as they had been in the tarball, so alien works only if the original tarball has files that should be installed off the root (/) directory of the system.
The syntax for alien:
alien [options] file[...]
Common alien options:
| Option | Description |
--to-deb |
Converts to Debian package. Note: This is the default option if no option is explicitly provided. |
--to-rpm |
Converts to RPM package. |
--to-slp |
Converts to Stampede package. |
--to-tgz |
Converts to tarball format. |
--install |
Installs the converted package and removes the converted file. |
As an example, to convert a Debian package called myprogram-1.0.1-3_i386.deb to an RPM:
# alien --to-rpm myprogram-1.0.1-3_i386.deb
To install a tarball on a Debian-based system and keep a record of the files it contains in the Debian package database:
# alien --install binary-tarball.tar.gz
Note: The important thing to remember is that converting a tarball converts the files in the directory structure of the original tarball using the system’s root directory as the base. As such, it may be necessary to unpack the tarball, shuffle the files around, and then repack it to get the desired results before installing it with alien.
Package Dependencies and Conflicts
The usual sources of problems relate to unsatisfied dependencies or conflicts between packages.
Real and Imagined Package Dependency Problems
Package dependencies and conflicts can arise for a variety of reasons:
| Reason | Details |
| Missing Libraries or Support Programs | A missing support package is one of the most common dependency problems. For example, all KDE programs rely on Qt, a widget set that provides assorted GUI tools. If Qt is not installed, no KDE packages will be able to be installed using RPM or Debian packages. Libraries — support code that is used by many different programs — are also a common source of problems. |
| Incompatible libraries or Support Programs | Even if a library or support program is installed, it may be the wrong version. For example, if a program requires Qt 4.8 but Qt 3.3 is installed, it will not run. Fortunately, Linux library-naming conventions allow for the installation of multiple versions of a library. |
| Duplicate Files or Features | A conflict can arise when one package includes files that are already installed and belong to another package. |
| Mismatched Names | Sometimes package names between RPM and Debian distributions do not match across different distributions. For example, if one package checks for another package by name, the first package may not install, even if the appropriate package is installed with a different name. |
Workarounds for Package Dependency Problems
The options to confront an unmet package dependency or conflict include:
- Forcing the installation.
- Modifying the system to meet the dependency.
- Rebuilding the problem package from source code.
- Finding another version of the problem package.
Forcing the Installation
The --nodeps parameter can be used to ignore failed dependencies using rpm:
# rpm -i package.rpm --nodeps
The --force parameter can be used to force installation despite errors (such as conflicts with existing packages):
# rpm -i package.rpm --force
Note: It is not recommended to use --nodeps or --force without first determining the reason for ignoring the dependency checks and errors preventing installation without these parameters.
For dpkg, the --ignore-depends=<package>, --force-depends, and --force-conflicts parameters can be used to overcome dependency and conflict problems on Debian-based systems.
Upgrading or Replacing the Depended-on Package
The proper way to overcome a package dependency problem is to install, upgrade, or replace the depended-on package. For example, if a program requires Qt 4.8+, the older version currently installed should be upgraded to that version.
Rebuilding the Problem Package
Rebuilding a package from source code can overcome some dependencies.
Fedora (and other developer-oriented RPM-based systems) include commands to rebuild RPM packages if the source RPM for the package is available:
# rpmbuild --rebuild packagename-version.src.rpm
The above command extracts the source code and executes whatever commands are required to build a new package (or sometimes several new packages). The output of this command should be one or more binary RPMs located in /usr/src/<distname>/RPMS/<arch>.
Note: Older versions of RPM use the rpm command instead of rpmbuild.
Be aware that compiling a source package typically requires the appropriate development tools to be installed, such as the GNU Compiler Collection (GCC) and other assorted development libraries.
Development Libraries (which typically include “dev” or “devel” in their names) are the parts of a library that enable programs to be written for the library.
Locating Another Version of the Problem Package
Sites like RPMFind (http://www.rpmfind.net/) and Debian’s package listing (http://www.debian.org/distrib/packages/) can be useful in tracking down alternative versions of a package.
Startup Script Problems
In the past, most Linux distributions used SysV startup scripts, but these scripts weren’t always transportable between distributions. For instance, systemd has become a more common startup option, and SysV scripts are not compatible with systemd.
Possible workarounds include:
- Modifying the included startup scripts.
- Building a new script based on another one from the distribution in use.
- Using a local startup script (such as
/etc/rc.d/rc.localor/etc/rc.d/boot.local).
Note: Startup script problems affect only servers and other programs that are started automatically when the computer boots; they do not affect typical user applications or libraries.
Managing Shared Libraries
Most Linux software relies heavily on shared libraries.
Libraries are software components that can be used by many different programs.
Library Principles
The idea behind a library is to simplify the lives of programmers by providing commonly used program fragments. For example, one of the most important libraries is the C library (libc), which provides many of the higher-level features associated with the C programming language.
Another common type of library is associated with GUIs. These libraries are often called widget sets because they provide onscreen widgets used by programs — buttons, scroll bars, menu bars, etc. The GIMP Tool Kit (GTK+) and Qt are the most popular Linux widget sets, and both ship largely as libraries.
Programmers choose libraries, not users; and one library cannot be substituted for another (the main exception being minor version upgrades).
Note: Linux uses the GNU C library (glicb) version of the C library. As of glibc 2.15, the main glibc file is usually called /lib/libc.so.6 or /lib64/libc.so.6, but this file is sometimes a symbolic link to a file of another name, such as /lib/libc-2.15.so.
Most programs use their libraries as shared libraries (aka dynamic libraries). This approach helps keep program file size down, enables sharing of the memory consumed by libraries across programs, and enables programs to take advantage of improvements in libraries by upgrading the library.
Note: Linux shared libraries are similar to the dynamic link libraries (DLLs) of Windows. Windows DLLs are usually identified by .dll filename extensions. In Linux, however, shared libraries usually have a .so or .so.<version> extension (.so stands for shared object). Linux static libraries (used by linkers for inclusion in programs when dynamic libraries are not to be used) have .a filename extensions.
Linux uses library-numbering schemes to permit multiple versions of a library to be installed at once.
Note: Developers who create programs using particularly odd, outdated, or otherwise exotic libraries sometimes use static libraries. This enables them to distribute their binary packages without requiring users to obtain and install their oddball libraries. Likewise, static libraries are sometimes used on small emergency systems, which don’t have enough programs installed to make the advantages of shared libraries worth pursuing.
Locating Library Files
The major administrative challenge of handling shared libraries involves enabling programs to locate those shared libraries.
Binary program files can point to libraries either by name alone (as in libc.so.6) or by providing a complete path (as in /lib/libc.so.6). In the first case, you must configure a library path — a set of directories where programs should search for libraries.
After making a change to the library path or complete path, you may need to use a special command to get the system to recognize the change.
Setting the Path System Wide
The first way to set the library path is to edit the /etc/ld.so.conf file.
This file consists of a series of lines, each of which lists one directory in which shared library files may be found. Typically, this file lists between half a dozen and a couple dozen directories. These lines begin with the include directive — which lists files that are to be included as if they were part of the main file. For example, Ubuntu 12.04’s ld.so.conf file begins with:
include /etc/ld.so.conf.d/*.conf
The above line tells the system to load all of the files in /etc/ld.so.conf.d whose name ends in .conf as if they were part of the main /etc/ld.so.conf file.
Some distributions, such as Gentoo, do something a little different but with the same goal. With these distributions, the env-update utility reads files in /etc/env.d to create the final form of several /etc configuration files, including /etc/ld.so.conf. In particular, the LDPATH variables in these files are read, and their values make up the lines in the ld.so.conf file. Thus, to change ld.so.conf in Gentoo or other distributions, you should add or edit files in /etc/env.d and type env-update to finalize the changes.
Library package files usually install themselves in directories that are already on the path or add their paths automatically. However, if you installed a library package, or a program that creates its own libraries, in an unusual location via mechanisms other than your distribution’s main package utility, you may need to change the library path system wide.
After changing the library path, the ldconfig command must be run to have programs use the new path.
Note: In addition to the directories specified in /etc/ld.so.conf, Linux refers to the trusted library directories, /lib and /usr/lib. These directories are always on the library path, even if they aren’t listed in the ld.so.conf file.
Temporarily Changing the Path
The LD_LIBRARY_PATH environment variable can be set to a directory (or directories) containing shared libraries:
$ export LD_LIBRARY_PATH=/usr/local/testlib:/opt/newlib
This environment variable accepts a single directory or multiple directories, separated by colons.
Directories specified in LD_LIBRARY_PATH are added to the start of the search path, making them take precedence over other directories.
A user’s shell startup script files can be edited to permanently set the LD_LIBRARY_PATH environment variable, if desired.
In principle, the LD_LIBRARY_PATH environment variable could be set globally; however, using the /etc/ld.so.conf file is the preferred method of effecting global changes to the library path.
Unlike other library path changes, this one doesn’t require that you run ldconfig for it to take effect.
Correcting Problems
$ gimp
gimp: error while loading shared libraries: libXinerama.so.1:
cannot~CA
open shared object file: No such file or directory
The above error message indicates that the system couldn’t find the libXinerama.so.1 library file. The usual cause of such problems is that the library isn’t installed, so you should look for it using commands such as find. If the file isn’t installed, try tracking down the package to which it should belong using a web search and install it.
If the library file is available, its directory may need to be added globally or to the LD_LIBRARY_PATH environment variable.
Sometimes the library’s path is hard-coded in the program’s binary file (this can be checked with ldd). When this happens, you may need to create a symbolic link from the location of the library on your system to the location that the program expects.
A similar problem can occur when the program expects a library to have one name but the library has another name on your system. For example, a program may link to biglib.so.5, but biglib.so.5.2 is installed. Since minor version number changes are usually inconsequential, creating a symbolic link should correct this problem:
# ln -s biglib.so.5.2 biglib.so.5
Note: This command must be run as root in the directory where the library resides, and ldconfig must be run thereafter.
Library Management Commands
The ldd program displays a program’s shared library dependencies — the shared libraries that a program uses.
The ldconfig program updates caches and links used by the system for locating libraries — that is, it reads /etc/ld.so.conf and implements any changes in that file and any directories it refers to.
Displaying Shared Library Dependencies
If a program won’t launch because of missing libraries, the first step is to check which libraries it uses:
$ ldd /bin/ls
Each line of output from ldd begins with a library name. If the library name doesn’t contain a complete path, ldd attempts to find the true library and displays the complete path following the => symbol.
The ldd command accepts a few options. The most notable of these is probably -v, which displays a long list of version information following the main entry. This information may be helpfulin tracking down which version of a library a program is using, in case there are multiple versions installed on your system.
Libraries can also depend on other libraries, which means ldd can be used on libraries as well. This can be useful if all the dependencies are met for a program but it still fails to load due to missing libraries.
Rebuilding the Library Cache
Linux (or, more precisely, the ld.so and ld-linux.so programs, which manage the loading of libraries) doesn’t read /etc/ld.so.conf every time a program runs. Instead, the system relies on a cached list of directories and the files they contain, stored in binary format in /etc/ld.so.cache.
This list is maintained in a format that’s much more efficient than a plain-text list of files and directories. The drawback is that it must be rebuilt every time libraries are added or removed. These changes include additions or removals of both the contents of the library directories and adding or remove the directories themselves.
The tool to update the /etc/ld.so.cache file is ldconfig:
# ldconfig
Common options to modify ldconfig:
| Feature | Option | Description |
| Display Verbose Information | -v |
Displays a summary of directories and files being registered. |
| Do Not Rebuild the Cache | -N |
Prevents a rebuild of the library cache, but updates symbolic links to libraries. |
| Process Only Specified Directories | -n <dirs> |
Ignores the directories specified in /etc/ld.so.conf and the trusted directories (/lib and /usr/lib), but updates directories (<dirs>) passed as arguments. |
| Do Not Update Links | -x |
Opposite of -N. It updates the library cache, but does not update symbolic links to libraries. |
| Use a New Configuration File | -f <conf-file> |
Changes the configuration file from /etc/ld.so.conf to whatever file is specified by <conf-file>. |
| Use a New Cache File | -c <cache-file> |
Changes the cache file from /etc/ld.so.cache to whatever file is specified by <cache-file>. |
| Display Current Information | -r <dir> |
Treat <dir> as if it were the root (/) directory. Note: This option is helpfulif recovering from a badly corrupted system, or if installing a new OS. |
Both RPM and Debian library packages typically run ldconfig automatically after installing or removing packages.
Managing Processes
When you type a command name, that program is run and a process is created for it.
Understanding the Kernel: The First Process
The Linux kernel is at the heart of every Linux system.
The uname command can be run to reveal details about the kernel being run.
Common options for uname:
| Display | Option | Description |
| Node Name |
|
Displays the system’s node name / network hostname. |
| Kernel Name | -s--kernel-name |
Displays the kernel name (typically ‘Linux‘ on a Linux system). |
| Kernel Version | -v--kernel-version |
Displays kernel version (usually a kernel build date and time, and not an actual version number). |
| Kernel Release | -r--kernel-release |
Displays the actual kernel version number. |
| Machine | -m--machine |
Displays information about the machine (generally CPU code, such as x86_64 or i686, etc.). |
| Processor | -p--processor |
May display information about the CPU; such as, manufacturer, model, and clock speed. In most cases it just returns ‘unknown‘ though. |
| Hardware Platform | -i--hardware-platform |
Is supposed to display hardware information but often returns just ‘unknown‘. |
| OS Name | -o--operating-system |
Returns the OS name (normally ‘GNU/Linux‘ on a Linux system). |
| Print All Information | -a--all |
Displays all available information. |
Examining Process Lists
One of the most important tools in process management is ps — which displays processes’ statuses:
ps [options]
Using Usefulps Options
The ps command supports three option types:
| Type | Syntax | Description |
| Unix98 Options | -<option> |
Single-character options, can be grouped together. Ex. ls -al |
| BSD Options | <option> |
Single-character options, can be grouped together. Ex. ps U <username> |
| GNU Long Options | --<option> |
Multi-character options (strings), cannot be grouped together. Ex. firewall-cmd --zone=public --permanent --add-port=22652/tcp |
The reason for so many supported option types is because the ps utility has historically varied a lot from one Unix OS to another, and support for almost all different implementations has been included with ps on most major Linux distributions. This behavior can be changed by setting the PS_PERSONALITY environment variable to posix, old, linux, bsd, sun, digital, etc.
Usefulfeatures for ps:
| Feature | Option | Description |
| Display Help | --help |
Summarizes common ps options. |
| Display All Processes | -A-e |
By default, ps displays only processes that were run from its own terminal (xterm, text-mode login, or remote login). The -A and -e options cause it to display all of the processes on the system, and the x option owned by the user that gives the command. |
| Display One User’s Processes | -u <user>U <user>--User |
Display processes owned by a particular user. <user> may be a username or user ID. |
| Display Extra Information | -f, -l,j, l, u, v |
Expands the information provided in the ps output. |
| Display Process Hierarchy | -H-f--forest |
Groups processes and uses indentation to show the hierarchical relationship between processes. |
| Display Wide Output | -ww |
The ps command limits output to only 80 characters in width, and truncates anything past that. These options tell ps not to do that. This can be helpfulif writing information to a file:$ ps w > ps.txt |
Interpreting ps Output
The output from the ps command typically starts with a heading line, which displays the meaning of each column:
| Column | Details |
| Username | The name of the user running this program/process. |
Process ID (PID) |
A number that’s associated with the process. |
Parent Process ID (PPID) |
The PID for the parent process spawning this process. |
| TTY | The teletype (TTY) is a code used to identify a terminal. Note: Not all processes have a TTY number; only text-mode programs do. |
| CPU Time | The TIME and %CPU headings are two measures of CPU time used. The first indicates the total amount of CPU time consumed, the second represents the percentage of CPU time the process is using when ps executes. |
| CPU Priority | The NI column, if present, lists the priority codes. The default value is 0. Positive values represent reduced priority, and negative values represent increased priority. |
| Memory Use | RSS is the resident set size (the memory used by the program and its data), and %MEM is the percentage of memory the program is using.Some outputs include a SHARE column, which is memory that’s shared with other processes (such as shared libraries). |
| Command | The final column in most listings is the command that was used to launch the process. |
Note: To find specific processes and their PIDs:
$ ps ax | grep <command>
Processes that aren’t linked to others were either started directly by init, or have had their parent processes killed and were “adopted” by init.
top: A Dynamic ps Variant
top is a useful command to display task manager of sorts, which displays information such as which processes are consuming CPU time relative to one another.
By default, top sorts entries by CPU use, and it updates the display every few seconds.
There are also GUI variants of top, such as kpm and gnome-system-monitor.
Common top options:
| Option | Description |
-d <delay> |
Changes the update time to <delay> seconds (default: 5). |
-p <pid> |
Monitor specific processes by PID. Note: Specify up to 20 PIDs by using this option multiple times (once for each PID). |
-n <num> |
Display a specific number of updates then quit. |
-b |
Batch mode. Do not use normal screen-update commands. Useful for logging CPU use to a file. |
While top is running, interactive commands can be entered:
| Command | Description |
h? |
Displays help information. |
k |
Kills a process after prompting for its PID. |
q |
Quits top. |
r |
Change a process’s priority (i.e. renice) after prompting for its PID and a new priority value (negative to increase, positive to increase — max -20 / 19, default 0).Note: Only root may increase a process’s priority. |
s |
Prompts for a new update rate in seconds. |
P |
Sort by CPU usage (default). |
M |
Sort by memory usage. |
Note: To look at just memory usage, use the free command. It provides a quick reference of how much physical memory and swap memory is in use, and how much remains available.
One of the pieces of information provided by top is the load average, which is a measure of the demand for CPU time by applications (0.0 represents no load, 1.0 represents full load on a CPU core).
Note: Most computers these days include multiple CPUs or CPU cores. On such systems, the load average can equal the number of CPUs or cores before competition for CPU time occurs. For example, a quad-core CPU can go up to a load average of 4.0 before any contention occurs between processes demanding CPU time. Typically, one program can create up to a load of 1.0; however, multithreaded programs can create higher load averages because they can take advantage of multiple CPUs, cores, or multithreaded cores.
The three load-average estimates displayed on the top line of top correspond to the current load average and two previous measures.
The current load average can also be found with the uptime command, which displays load averages along with information about how long the machine has been running for.
jobs: Processes Associated with Your Session
The jobs command displays minimal information about the processes associated with the current session, such as job ID numbers. These numbers are similar to PID numbers, but not the same.
Jobs are numbered starting from 1 for each session, and generally a single shell will only have a few associated jobs.
The jobs command can also be used to ensure all programs have terminated prior to logging out.
pgrep: Finding Processes
The pgrep command was introduced under the Solaris operating system. It performs a simple search within the process list (similar to ps piped to grep):
pgrep [-flvx] [-n | -o] [-d <delim>] [-P <ppidlist>] [-g <pgrplist>] [-s <sidlist>] [-u <euidlist>] [-U <uidlist>] [-G <gidlist>] [-J <projidlist>] [-t <termlist>] [-T <taskidlist>] [-c <ctidlist>] [-z <zoneidlist>] [pattern]
Processes can be searched based on username, user ID, or group ID; and can include an additional regular expression pattern:
$ pgrep -u root cron
The above command will search for processes named ‘cron’ that are run by the root user, and returns the process ID value of the processes that match.
Understanding Foreground and Background Processes
Normally, when a program is launched, it takes over the terminal, and prevents any other work from being done on that terminal (note: some programs do release the terminal).
Ctrl+z can pause the program and give control of the terminal back.
To get back to the program that was paused, use the fg command. This brings it back to the foreground of the terminal.
If multiple processes have been paused/suspended, a job number can be provided to the fg command to ensure it brings that specific process back to the foreground:
$ fg 2
A variant on fg is the bg command, which brings a job to the background and keeps it running, while restoring access to the terminal.
The bg command is often usefulwhen launching GUIs from the command line — as the shell window that launched the program is tied up while the GUI is being displayed. Pressing ctrl+z on the command line will pause the GUI program, and then entering the bg command will unfreeze it as it gets moved to the background of the terminal.
An alternative to using ctrl+z then bg, is to append an ampersand (&) to the command when launching the program:
$ nedit myfile.txt &
The above command will launch the nedit program in the background from the start.
Managing Process Priorities
The nice command can be used to launch a program with a specific priority, and the renice command can be used to alter the priority of a running program.
The nice command has the following syntax:
nice [argument] [command [command-arguments]]
There are three ways to specify a priority value to nice:
nice -<value>nice -n <value>nice --adjustment=<value>
For example, setting a positive 12 value for a fictitious fold-protein command:
$ nice -12 fold-protein data.txt$ nice -n 12 fold-protein data.txt$ nice --adjustment=12 fold-protein data.txt
If the priority value is omitted from the nice command, it will default to a value of 10. If nice is not used at all, the default priority value is 0.
The range of possible values for priority is -20 to 19. The greater the negative number, the higher the priority.
Only the root user can launch a program with increased priority (negative priority value), but any user can launch a program with decrease priority (positive priority value).
The renice command has the following syntax:
renice <priority> [[-p] <pids>] [-g <pgrps>] [-u <users>]
The renice command accepts one or more PIDs (pids), one or more group IDs (pgrps), or one or more usernames (users). If using pgrps or users, renice changes the priority of all programs that match the specific criteria — but only root may use renice this way. In addition, only the root user may increase a process’s priority (by lowering the priority value).
If a numeric value is provided after the priority, without -p, -g, or -u, renice assumes the value is a PID.
An example of using renice:
# renice 7 16519 -u jeff josh
The above command would change the priority to 7 for PID 16519 for the users jeff and josh.
Killing Processes
The kill command can be used to terminate a program by sending a signal to a specific process. This signal is usually sent by the kernel, the user, or the program itself to terminate the process.
Note: The kill command will only kill processes owned by the user that runs kill, with the exception of the root user — which may kill any users’ processes.
Linux supports many numbered signals, each associated with a specific name. They can be listed with:
kill -l
The kill command has the following syntax:
kill -s <signal> <pid>
The -s <signal> parameter sends the specific signal to the process.
The signal can be specified as either a number, or as its corresponding name. The most commonly used signals are:
1/SIGHUP— terminates interactive programs and causes many daemons to reread their configuration files.9/SIGKILL— exits a process without performing routine shutdown tasks.15/SIGTERM— exits a process but allows it to close open files, etc.
If no signal is specified, 15 / SIGTERM is used as a default.
An alternative option to using a signal number or name, is to use the -signal option. When using this option, omit the SIG portion of the signal name:
kill -signal TERM 5219
The above command would send the SIGTERM / 15 signal to the process with a PID of 5219.
Note: Although Linux includes a kill program, many shells, including bash and csh, include a built-in kill equivalent. To be sure that the external program is buing used, type the full path to /bin/kill.
The kernel can pass signals to programs, even if you do not use the kill command. For example, when logging out of a session, the programs you started from that session are sent the SIGHUP / 1 signal, causing them to terminate.
To keep a program running after logging out, it can be ran with the nohup command:
$ nohup <program> <options>
The nohup command causes the program to ignore the SIGHUP / 1 signal.
A variant of the kill command is the killall command:
killall [options] [--] <name> [...]
The killall command kills a process based on its name rather than its PID number.
The default signal for killall is also 15 / SIGTERM.
An important option for the killall command is -i. This option will cause killall to prompt for confirmation before sending a signal to each process it matches:
$ killall -i vi
Kill vi(13219) ? (y/n)
It is highly recommended to always use the -i option when running killall as the root user.
Note: Some versions of Unix provide a killall command that works very differently from Linux’s killall command. This alternative version kills all of the processes started by the user who runs the command. To ensure you do not use this more destructive version of the command, check the man page for the system’s killall command first.
Another variant on kill is the pkill command:
pkill [-signal] [-fvx] [-n | -o] [-P <ppidlist>] [-g <pgrplist>] [-s <sidlist>] [-u <euidlist>] [-U <uidlist] [-G <gidlist>] [-J <projidlist>] [-t <termlist>] [-T <taskidlist>] [-c <ctidlist>] [-z <zoneidlist>] [pattern]
The pkill command can kill one or more processes based on usernames, user IDs, group IDs, and other features, in addition to a regular expression for matching.
The pkill command was introduced on the Solaris operating system.
Package Manager, Library, and Process Essentials
Most distributions are built around the RPM or Debian package systems, both of which enable installation, upgrade, and removal of software using a centralized package database to avoid conflicts and other problems that are common when no central package database exists.
Yum and APT can be used to assist with keeping a system synchronized with the latest versions of software.
Shared libraries are the necessary building blocks of large programs. Sometimes they need to be configured or upgraded manually.
Processes can be paused, manipulated as foreground or background processes, have their priorities set, or even killed.
Things to know without lookup:
- Identify critical features of RPM and Debian package formats:
- RPM and Debian packages store all of the files for a given package in a single file that also includes information about what other packages the software depends on.
- RPM and Debian systems maintain a database of installed packages and their associated files and dependencies.
- Describe the tools used for managing RPMs:
- The
rpmprogram is the main tool for installing, upgrading, and uninstalling RPMs. - The Yum utility, and particularly its
yumcommand, enables installation of a package and all of its dependencies via the Internet rather than from local package files.
- The
- Describe the tools used for managing Debian packages:
- The
dpkgprogram installs or uninstalls a single package or group of packages that are specified. - The
apt-getutility retrieves programs from installation media or from the Internet for installation, and can automatically upgrade an entire system. - The
dselectprogram serves as a text-mode menu-driven interface toapt-get.
- The
- Summarize tools for extracting files and converting between package formats:
- The
rpm2cpioprogram can convert an RPM file into acpioarchive, enabling non-RPM systems to access files in an RPM.<\li> - The
alienutility can be used to convert packages between Debian, RPM, Stampede, and also tarballs. This enables the use of packages intended for one system onto another.
- The
- Summarize the reasons for using shared libraries:
- Shared libraries keep disk space and memory requirements manageable by placing code that’s needed by many programs in separate files from the programs that use it, enabling one copy to be used multiple times.
- Shared libraries act as basic building blocks for programmers to use in their programs, so that they do not have to reinvent code for common tasks constantly.
- Describe methods available to change the library path:
- The library path can be changed system wide by editing the
/etc/ld.so.conffile followed by theldconfigcommand to ensure the cache has been updated.<\li> - For temporary or per-user changes, directories may be added to the library path by placing them in the
LD_LIBRARY_PATHenvironment variable.
- The library path can be changed system wide by editing the
- Explain the difference between foreground and background processes:
- Foreground processes have control over the current terminal or text-mode window (such as
xterm). - Background processes do not have exclusive control over a terminal or text-mode window, but are still running.
- Foreground processes have control over the current terminal or text-mode window (such as
- Describe how to limit the CPU time used by a process:
- A program may be launched with the
nicecommand to set its priority from the beginning. - A running program can have its priority changed using the
renicecommand after it has been started. - Processes can be terminated with the
killorkillallcommands.
- A program may be launched with the
Foreword
For further studying I highly recommend purchasing and accessing the following:
CompTIA Linux+ Powered by Linux Professional Institute Study Guide: Exam LX0-103 and Exam LX0-104 3rd Edition
by Christine Bresnahan and Richard Blum
Exam Review for CompTIA Linux+ (LX0-103) and LPI LPIC-1 (101-400)
By Andrew Mallett
Command Line
Exam Objectives
- 103.1 – Work on the command line
- 103.2 – Process text streams using filters
- 103.4 – Use streams, pipes, and redirects
- 103.7 – Search text files using regular expressions
Shells
A shell is a program that accepts and interprets text-mode commands and provides an interface to the system.
The most commonly used shell is bash (GNU Bourne Again Shell), and it is most emphasized on the exam.
There are two types of default shells:
- Default interactive shell – The shell program a user uses to enter commands, run programs/scripts, etc.
- Default system shell – Used by the Linux system to run system shell scripts (typically at start-up).
The /bin/sh file is a pointer to the system’s default system shell, which is normally /bin/bash for Linux.
To access a shell you can either log into Linux via text-mode, or load a GUI such as terminal, xterm, konsole, etc. Either option will bring you to the default interactive shell.
To use a shell you simply type a command, possibly add options and/or a path to it, and then the computer executes the command.
Internal and External Commands
Most commands are external but some commands are internal (built-in) to the shell itself.
The most common internal commands are:
| Command | Description |
cd |
Changes directories |
pwd |
Prints the current working directory |
echo |
Displays text |
time <cmd> |
Outputs the time it takes to execute <cmd>. Three times are displayed:
|
set |
Used to set shell variables (which are similar to environment variables but not the same thing) |
logout |
Terminates login shells (shells used in text-mode) |
exit |
Terminates any shell |
To determine if a command is internal or not, you can use the type command:
$ type <command>
$ type type
type is a shell builtin
Some commands also have a duplicate external command in addition to the internal command of the same name. To check for duplicates:
$ type -a <command>
$ type -a pwd
pwd is a shell builtin
pwd is /bin/pwd
Internal commands take precedence over external commands when both are present. In order to access an external command you must provide the complete external command path (ex. /usr/bin/time rather than time).
When a command is ran the shell checks for an internal command first. If none is found, it will check for external command within any of the directories listed in the $PATH environment variable.
If a command is not internal or present on the $PATH, it can be run by providing a full path name on the command line.
In order for any file to be ran it must have the executable bit marked on its file permissions (ex. -rwxr--r--).
To adjust a file’s permissions you can use the chmod command:
$ chmod <options> <file>
$ chmod +x script.sh
BASH Navigation
Filenames can be up to 255 characters in length on most filesystems.
The tilde (~) character can be used as a shortcut to represent the current user’s home directory path (ex. ~ translates to /home/jeff when logged in as the user named jeff).
When bash is invoked as an interactive login shell it reads commands from a files /etc/profile. After that, it will attempt to read another file at ~/.bash_profile, ~/.bash_login, and ~/.profile (in that order).
When an interactive shell that is not a login shell is started, bash reads and executes commands from a ~/.bashrc file, if it exists.
When a login shell exits, bash processes any commands from files at ~/.bash_logout and /etc/bash.bash_logout, if those files exist.
Pressing the tab key will cause the shell to try to fill out the rest of the command or filename. If there are multiple possible matches, it will display them when you press the tab key a second time. This is called command completion, which is supported in bash and tcsh.
The bash shell provides many hotkeys for navigation, based on the Emacs editor:
| Hotkey | Details |
^A / ^E |
Move cursor to start or end of line, respectively. |
^B / ^F |
Move the cursor backwards or forward one character. |
|
|
Moves the cursor backwards or forwards on word. |
|
|
Moves cursor from current position to the beginning, or from beginning back to previous position. |
^H |
Delete the character to the left of the cursor. |
^DDel |
Deletes the character under the cursor. |
^W |
Delete from cursor to start of a word (backwards). |
!D |
Delete from cursor to end of a word (forward). |
^U |
Delete to beginning of line. |
^K |
Delete to end of line. |
^Y |
Paste last text deleted/removed. |
^T |
Transpose the character before and under the cursor. |
!T |
Transpose the words before or under the cursor. |
!U |
Converts to UPPERCASE. |
!L |
Converts to lowercase. |
!C |
Converts to Capitalize Case. |
^X → ^E |
Launch Emacs or any editor defined by $FCEDIT or $EDITOR environment variables. |
^L |
Clear output (same as using the command clear) |
^S |
Stops the flow of output (but does not stop execution). |
^Q |
Resumes showing the flow of output. |
^Z |
Suspends anything currently being executed and places it into the jobs queue. |
^C |
Sends an interrupt to kill the currently running process. |
History
The shell keeps a log of every command you type, called history. To access this history:
$ history
The following hotkeys can be used for navigating the history:
| Hotkey | Details |
Up / Down |
Cycle through previous commands in history. |
^P / ^N |
Same as Up / Down. |
Esc → < |
Go to first item in history. |
Esc → > |
Go to last item in history. |
!. |
Insert the last word from the previous command. |
^R |
Starts a reverse text search through history. Press ^R to move backwards through all matches. |
^S |
Moves forwards through all matches in an existing reverse search. |
^Q |
Quits the search (useful if it hangs). Note: Using $ stty -ixon can prevent hanging. |
^G |
Terminate search. |
To retrieve and execute the last command in history:
$ !!
To run the most recent command in history starting with a particular string:
$ !<characters>
To re-use the first argument of the previous command:
$ !^
To re-use the last argument of the previous command:
$ !$
To re-use all arguments from the previous command:
$ !*
To execute a particular item within history:
$ !<number>
$ !210
Note: To display what any of these shortcut expressions translate to, add :p to the end. For example, $ !*:p.
The bash history file is stored at ~/.bash_history (i.e. within your user’s home directory).
The bash history does not store what you type in response to other prompts made by commands or programs. Because of this, it is advisable to not enter sensitive information (passwords, SSNs, etc.) as an argument to a command, but rather enter it when prompted by the command being run.
Environment Variables
Environment variables hold data that can be referred to by variable name.
These variables (and their data) are available to all programs, including the shell itself.
All environment variables can be displayed with:
$ env
To view the particular data an environment variable is holding:
$ echo $<env_name>
To assign an environment variable:
$ <env_name>="<env_value>"
$ export <env_name>
Alternatively, you can do it in one line:
$ export <env_name>="<env_value>"
To delete an environment variable:
$ unset <env_name>
Some common environment variables:
| Name | Description | Example Value |
PS1 |
The prompt displayed during a shell session. | [\u@\h \W]\$ |
PATH |
A list of colon-seperated directories that the shell checks to run external commands when a full path isn’t provided. |
/usr/lib64/qt-3.3/bin: |
TERM |
Details about the shell/terminal in use. | xterm |
Getting Help
Linux provides several commands to lookup information on other commands:
| Command | Description |
man |
Manual pages that provide succinct summaries of what a command, file, or feature does. |
info |
Similiar to man but uses hypertext format rather than plain text. |
help |
Specifically for internal (built-in) commands. |
By default, man uses the less pager to display the manual pages.
To use another pager with man:
$ man -P <path_to_pager> <command>
Most Linux distributions provide a whatis database, which contains short descriptions of each man page and keywords for searches.
To create or update a whatis database:
$ makewhatis
To search man pages by keyword:
$ man -k "<keyword1 keyword2 ... keywordN>"
Man pages can be broken down into several sections based on number:
| Section Number | Description |
| 1 | Executable programs and shell commands |
| 2 | System calls provided by the kernel |
| 3 | Library calls provided by program libraries |
| 4 | Device files (usually stored in /dev) |
| 5 | File formats |
| 6 | Games |
| 7 | Miscellaneous (macro packages, conventions, and so on) |
| 8 | System administrator commands (programs run mostly or exclusively by root) |
| 9 | Kernel routines |
Man generally returns the lowest-numbered section, but you can force it to display a particular section number with:
$ man <section_num> <command>
Less Pager Navigation
The less pager provides several hotkeys to navigate with:
| Hotkey | Description |
Space |
Move forward a page. |
b |
Move back a page. |
Esc → v |
Move back a page. |
j / kUp / Down |
Move up or down a line. |
g / Left |
Go to first line. |
G / Right |
Go to last line. |
/<text> |
Start a forward search for text. |
?<text> |
Start a reverse search for text. |
n |
Cycle search forward. |
N |
Cycle search backwards. |
q |
Quit |
Streams, Pipes, and Redirection
In order to move input and output between programs and/or files we use streams, pipes, and redirection.
Linux treats input and output from programs as a stream — which is a data entity that can be manipulated.
Input and output streams can be redirected from or to other sources, including files. Similarly, output from one program can be piped to another program as its input.
File Descriptors
Linux handles all objects as files — including a program’s input and output stream.
To identify a particular file object, Linux uses file descriptors:
| Name | Abbreviation | File Descriptor | Details |
| Standard Input | STDIN |
0 |
Programs accept keyboard input via STDIN. |
| Standard Output | STDOUT |
1 |
STDOUT is normally displayed on the screen, either in a full-screen text-mode session or a GUI terminal, such as xterm or konsole. |
| Standard Error | STDERR |
2 |
STDERR is intended to carry high-priority information such as error messages. Ordinarily it is sent to the same output devices as STDOUT, but either can be redirected independently of the other. |
Redirects
Input and output can be redirected by using specific operators following a command and its options:
| Operator | Effect |
>1> |
Creates a new file containing STDOUT.File overwritten if exists. |
>>1>> |
Appends STDOUT to the existing file. File created if not exists. |
2> |
Creates a new file containing |
2>> |
Appends standard error to the existing file. File created if not exists. |
&> (bash) |
Creates a new file containing both standard output and standard error. File overwritten if exists. |
< |
Sends the contents of the file to be used as standard input. |
<< |
Accepts text on the following lines as standard input. |
<> |
Causes the specified file to be used for both standard input and standard output. |
Pipes
Data pipes (a.k.a. pipelines) can be used to send STDOUT from one program to the STDIN of another program:
$ first_program | second_program
Using a pipe is functionally equivalent to:
$ first_program > temp_file && second_program < temp_file
Tee
The tee command is often used with pipes to split STDOUT so that it’s both displayed on screen and sent to a file:
$ echo $PATH | tee path.txt
/usr/lib64/qt-3.3/bin:/usr/local/bin:[...]
Note: tee will overwrite files unless you pass the -a option to it.
Generating Commands
The xargs command passes its STDIN as the STDIN to whichever command you wish:
$ xargs [options] [command [initial-arguments]]
By default, xargs delimits its input by spaces and newlines. To force a particular character to use for delimiting, use the -d option:
$ find / -user jeff | xargs -d "\n" rm
Enclosing a command within backticks (`) works similarly to xargs:
$ rm `find ./ -user jeff`
Since backticks can sometimes not work very well in complex situations, enclosing commands with a $() is generally preferred:
$ rm $(find ./ -user jeff)
Text Filters
The cat, join, and paste commands all join files end-to-end based on fields within the file, or by merging on a line-by-line basis.
Cat / Tac
The cat command is short for the word concatenate. It combines the contents of files together and sends the data to STDOUT:
$ cat first.txt second.txt > combined.txt
It can also be used to display the contents of a file to the screen when using cat without a redirect:
$ cat hello_world.txt
hello world!
Common options for cat:
| Option | Description |
-E--show-ends |
Shows a dollar sign ($) at the end of each line. |
-s--squeeze-blank |
Compresses groups of blank lines to a single blank line. |
-n--number |
Adds a number to the beginning of every line. |
-b --number-nonblank |
Adds a number for non-empty lines. |
-T--show-tabs |
Shows all tab characters as ^l. |
-v--show-nonprinting |
Shows most control and other special characters using ^ (carat) and M- notations. |
tac is the same as cat, but it reverses the order of lines in the output.
Join
The join command combines two files by matching their contents on a delimited field specified by the user:
$ join file1.txt file2.txt
006 Trevelyan, Alec deceased
007 Bond, James active
By default, join uses a space character as the field delimiter. However, the delimiter can be changed with the -t option:
$ join -t “,” file1.txt file2.txt
The join command also defaults to using the first delimited field for matching. This can be changed by using an option corresponding to the file number (ex. -1, -2, -3, …, -99) followed by the field number to use:
$ join -1 3 -2 2 file1.txt file2.txt
To specify the output format, use the -o option.
Paste
The paste command merges files line-by-line, separating the lines from each file with tabs:
$ paste file1.txt file2.txt
file1_line1 file2_line1
file1_line2 file2_line2
File Transforming Commands
Commands for transforming the contents of files doesn’t actually change their content, but you can redirect their STDOUT to a new file or pipe it to another command.
Sort
By default, the sort command will sort files by the first field using case-sensitive ASCII values.
Common options for sort:
| Option | Description |
-f--ignore-case |
Ignore case when sorting. |
-M--month-sort |
Sort by 3-letter month abbreviations. |
-n--numeric-sort |
Sort by number. |
-r--reverse |
Reverse sort order. |
-k--key= |
Specify the field to sort on. |
Delete Duplicate Lines
The uniq command removes duplicate lines within a file:
$ sort shakespeare.txt | uniq
Split
The split command can split a file into two or more files, which receive an automatically generated alphabetic suffix.
By default, split will create output files in 1,000-line chunks, with names ending in aa, ab, ac, etc.
Common options for split:
| Option | Description |
| -b –bytes= |
Break input file into pieces by byte size. |
-C=--line-bytes= |
Uses the maximum number of lines without exceeding a byte size. |
-l--lines= |
Specifies the number of lines the split files can contain. |
split works on STDIN if no input file is specified.
Translate Characters
The tr command changes individual characters from STDIN:
$ tr [options] SET1 [SET2]
SET1 is a group of characters to be replaced by SET2 (if supplied).
Because tr uses STDIN, redirection must be used to input from a file:
$ tr d D < file1.txt
tr supports a number of shortcuts to represent various character groups:
| Shortcut | Description |
[:alnum:] |
All letters and numbers. |
[:upper:] |
All UPPERCASE letters. |
[:lower:] |
All lowercase letters. |
[:digit:] |
All numbers. |
[A-Z] |
Ranges between the first character and the second character. |
Common options for tr:
| Option | Description |
| -t –truncate-set1 |
Truncates the size of SET1 to the size of SET2. |
-d |
Delete characters from SET1. SET2 is omitted with this option. |
Convert Tabs and Spaces
The expand command converts tab characters into spaces. Each tab becomes 8 spaces by default, but this can be changed with the -t or --tabs= options.
The unexpand command converts multiple spaces into tab characters. Just like expand, unexpand can use the -t or --tabs= options to specify the number of characters per tab.
Display Files as Byte Data
The od (octal dump) command can be used to display a file in an unambiguous byte data format, such as:
octal (base 8), hexadecimal (base 16), decimal (base 10), and even ASCII with escaped control characters.
By default, od will output as octal when called without options:
$ od file1.txt
0000000 032465 026465 031462 033471 072440 066156 071551 062564
0000020 005144 032465 026465 030465 033061 066040 071551 062564
0000040 005144 032465 026465 034467 034462 066040 071551 062564
[…]
The first field on each line is an index of the file in octal. The second line begins at octal 20 (16 in decimal) bytes into the file. The remaining numbers represent the bytes in the file.
File Formatting
The fmt, nl, and pr commands are used to reformat text within a file.
Fmt
fmt can be used to clean up files with long line lengths, irregular line lengths, or other problems.
By default, fmt will attempt to clean up paragraphs assumed to be delimited by two or more blank lines or by changes in indentation. The new paragraphs will be formatted to no more than 75 characters wide.
The width of formatted paragraphs can be changed with the -<width>, -w <width>, and --width=<width> options.
NL
nl adds number lines to a file (similar to cat -b).
By default, nl starts each new page on line 1. The -p or --no-renumber option will prevent the line number reset on each page.
-n <format> or --number-format=<format> can be used to change the numbering format:
| Format | Justification | Leading Zeros |
ln |
Left justified | – |
rn |
Right justified | – |
rz |
Right justified | YES |
The header, body, and footer of a page can be styled with -h <style>, -b <style>, and -f <style>.
Alternatively --header-numbering=<style>, --body-numbering=<style>, and --footer-numbering=<style>:
| Style Code | Description |
t |
Number lines that aren’t empty. (Default value) |
a |
All lines are numbered, including empty lines. |
n |
All line numbers omitted. |
pREGEXP |
Only lines that match the regular expression (REGEXP) are numbered. |
An example of using nl to add line numbers to a script:
$ nl -b a script.js > numbered-script.txt
The page delimiter can be set with -d=<code> or --section-delimiter=<code>.
<code> represents the character that identifies the new page.
PR
pr can be used to prepare a plain-text file for printing by adding headers, footers, page breaks, etc.
The pr command itself does not handle printing, but its output is often piped to the lpr command to actually handle printing.
By default, pr assumes an 80-character line length with a monospaced font; and outputs the original text with headers that include the current date, time, filename, and page number.
Common options for pr:
| Option | Description |
-<numcols>--columns=<numcols> |
Sets the number of columns to output text in. Note: If the lines are too long they are truncated or run over into multiple columns. |
-d--double-space |
Double-spaced output from a single-spaced file. |
-F-f--form-feed |
Creates a form-feed character between pages, rather than just using a fixed number of blank lines (default). |
-l <lines>--length=<lines> |
Sets the length of lines per page. |
-h <text>--header=<text> |
Sets the text to display in the header. |
-t--omit-header |
Removes the header entirely. |
-o <num>--indent=<num> |
Sets the indent to <num> characters. |
-w <num>--width <num> |
Sets the page width to <num> characters. (Default: 72). |
An example of using pr to print a double-spaced and numbered version of a configuration file at /etc/profile:
$ cat -n /etc/profile | pr -d | lpr
Note: The pr command was built around assumptions for printer capabilities back in the 80s. The command can still be useful today, but GNU Enscript (http://www.codento.com/people/mtr/genscript/) is preferred. This program has many of the same features as pr, but it generates PostScript output that can take better advantage of modern printers and their features.
File Viewing
Head
head echos the first 10 lines of one or more files to STDOUT.
If more than one file is passed to head, it will precede each file’s output with a header to identify it.
Common options for head:
| Option | Description |
-c <num>--bytes=<num> |
Display <num> bytes, rather than the default 10 lines. |
-n <num>--lines=<num> |
Display <num> lines. |
Tail
tail echos the last 10 lines of one or more files to STDOUT.
Common options for tail:
| Option | Description |
-c <num>--bytes=<num> |
Display <num> bytes, rather than the default 10 lines. |
-n <num>--lines=<num> |
Display <num> lines. |
-f--follow |
Keep file open and display new lines as they are added. |
--pid=<pid> |
Terminate tracking once the process ID (PID) of <pid> terminates. |
Note: head and tail can be combined to display or extract portions of a file. For example, if you want to display lines 11 – 15 of a file named sample.txt, you could extract the first 15 lines with head and display the last five of those with tail:
$ head -n 15 sample.txt | tail -n 5
Less / More
less is the successor to more (the joke being: “less is more“).
less enables you to read through a file one screen at a time:
$ less <filename>
To navigate the less pager:
| Hotkey | Description |
Space |
Move forward a page. |
b |
Move back a page. |
Esc → v |
Move back a page. |
j / kUp / Down |
Move up or down a line. |
g / Left |
Go to first line. |
G / Right |
Go to last line. |
/<text> |
Start a forward search for text. |
?<text> |
Start a reverse search for text. |
n |
Cycle search forward. |
N |
Cycle search backwards. |
q |
Quit |
Note: less cannot be used in a pipe, except as the final command.
Note 2: more cannot page backwards through a file.
File Summarizing
Cut
cut extractions portions of input lines and displays them on STDOUT.
Common options for cut:
| Option | Description |
-b <list>--bytes=<list> |
Cuts <list> of bytes from the input file. |
-c <list>--characters=<list> |
Cuts (Note: |
-f <list>--fields=<list> |
Cuts <list> of fields from input file. |
-d <char>--delim=<char>--delimiter=<char> |
Change the delimiter for fields to <char>.(Default: tab character). |
-s--only-delimited |
Prevents cut from echoing lines without delimited characters. |
<list> can be a single number (ex. 4), a closed range of numbers (ex. 2-4), or an open range of numbers (ex. -4 or 4-).
An example of using cut to extract the hardware address of a wireless adapter:
$ ifconfig wlp2s0 | grep ether | cut -d " " -f 10
e4:a4:71:66:24:ad
WC
wc produces a word count, line count, or byte count for a file:
$ wc file.txt
308 2343 15534 file.txt
The above output shows that file.txt contains 308 lines (308 newline characters), 2343 words, and 15534 bytes.
Common options for wc:
| Option | Description |
-l--lines |
Displays newline count. |
-w--words |
Displays word count. |
-c--bytes |
Displays byte count. |
-m--chars |
Displays character count. |
-L--max-line-length |
Displays length of longest line. |
Note: Character and byte counts are typically identical on most ASCII files, unless multibyte character encoding is used.
Regular Expressions
Regular Expressions (RegEx) are tools for describing or matching patterns in text:
| Name | Pattern / Example | Matches |
| Literal String | LinuxHWaddr |
LinuxHWaddr |
| Bracket Expression | b[aoeui]g |
bag, beg, big, bog, bug |
| Range Expression | [a-z][A-Z][0-9] |
Any |
| Any Character | . |
Every character but newline characters. |
| Start / End of Line | ^$ |
Modifier to represent start of line. Modifier to represent end of line. |
| Repetition Operators | *+? |
Zero or more times. One or more times. Zero or one time. |
| OR | car|trucka|b |
Either car or truck.Either a or b. |
| Subexpression | bat(man) |
batman for full match, man for substring. |
| Escape | alchemist\.digital |
alchemist.digital |
There are two forms of regular expressions: basic and extended.
More information on RegEx can be found with:
$ man 7 regex
Grep
grep searches for files that contain a specific string, returning the name of the file and a line of context for the match (if the file is a text file):
$ grep [options] <regexp> [files]
Common options for grep:
| Option | Description |
-c--count |
Displays the number of lines that match the pattern, instead of displaying context lines. |
-f <file>--file=<file> |
Reads a file for the <regexp> pattern. |
-i--ignore-case |
Ignores the case of the pattern being matched. |
-r--recursive |
Recursively searches a directory and all subdirectories. |
-F--fixed-strings |
Disable regex and use basic pattern searching instead. |
-E--extended-regexp |
Allows the use of extended regular expressions. |
An example of using grep with a regular expression:
$ grep -r eth0 /etc/*
The above command will recursively search for the pattern eth0 within all files of all directories inside of /etc, and any file found to match that string will be printed to STDOUT.
To find all files that contain a match for eth0 and eth1, the above command can be rewritten as:
$ grep -r eth[01] /etc/*
An example of using extended regular expressions with grep:
$ grep -E "(alchemist\.digital|mr2\.run).*169" /etc/*
The above command will search all files within the /etc directory for anything containing alchemist.digital or mr2.run with the number 169 on the same line.
Note: Sometimes shell quoting is necessary to ensure grep has a chance to use certain characters in a regular expression before the shell attempts to parse them for its own purpose (ex. |, *, etc.)
Sed
sed directly modifies a file’s contents and sends the changes to STDOUT.
There are two forms of syntax for sed:
$ sed [options] -f <script-file> [input-file]
$ sed [options] '<script-text>' [input-file]
[input-file] is the name of the file you want to modify.
The contents of <script-file> or <script-text> are a set of commands that sed will perform.
By default, commands operate on the entire file. However, an address (line number) can be provided to ensure the command only operates on the desired lines.
Addresses can be provided as either a single number or a range of two numbers separated by a comma.
Note: Addresses can also be provided as a regex pattern when using the -e option with sed.
Common commands used with sed:
| Command | Meaning |
= |
Display the current line number. |
a\<text> |
Append <text> to the file. |
i\<text> |
Insert <text> into the file. |
r <filename> |
Append text from <filename> into the file. |
c\<text> |
Replace the selected range of lines with the provided <text>. |
s/<regexp>/<replacement> |
Replace text that matches the regular expression (regexp) with <replacement>. |
w <filename> |
Write the current pattern space to the specified file. |
q |
Immediately quit the script, but print the current pattern space. |
Q |
Immediately quit the script. |
An example of using sed for text replacement:
$ sed 's/2012/2013/' cal-2012-txt > cal-2013.txt
Note: If no input file is specified, sed can use STDIN.
Convert Between Unix and DOS Line Endings
Unix (and Linux) use a single line feed character (ASCII 0x0a, sometimes represented as \n) as the end of a line in a file.
DOS and Windows use the combination of a carriage return (ASCII 0x0d or \r) and a line feed (i.e. \r\n).
To convert files from one system to another there is special-purpose programs such as dos2unix and unix2dos:
$ dos2unix file.txt
Alternatives
Since not all distributions have these utilities, an alternative to convert from DOS to Unix would be:
$ tr -d [[backslash backslash]]r < dosfile.txt > unixfile.txt
The above tr command is run with the -d (delete) option to remove all carriage returns (\r) using the escaped literal backslash in the set. The tr command’s input is the dosfile.txt file, and the output is redirected to the unixfile.txt file.
An alternative to convert from Unix to DOS style would be:
$ sed s/$/"\r"/ unixfile.txt > dosfile.txt
The above command uses the regexp of $ for the end of line, and replaces it with a \r (carriage return) in its place. The input for the command is the unixfile.txt and the redirected output goes into the dosfile.txt.
Note: Another option is to have a text editor save the file using a different file-type setting, but not all editors support this feature/option.
Command Line Essentials
Things to know without lookup:
- Summarize features that Linux shells offer to speed up command entry:
- Command history enables you to get an earlier command that is identical or similar to the one you want to enter.
- Tab completion reduces typing effort by letting the shell finish long command and file names.
- Command-line editing lets you edit a retrieved command or change a typo before submitting the command.
- Describe the purpose of the man command:
- man displays the manual page for a keyword (command, filename, system call, etc.) that you type.
- The information provided is a succinct summary that’s useful for reference or to learn about exact command options and/or features.
- Explain the purpose of environment variables:
- Environment variables store small pieces of data — program options, information about the machine, etc.
- This information can be read by programs and used to modify program behavior in a way that’s appropriate for the current environment.
- Describe the difference between standard output and standard error:
- STDOUT carries normal program output, whereas STDERR carries high-priority output, such as error messages.
- The two can be redirected independently of one another.
- Explain the purpose of pipes:
- Pipes tie programs together by feeding the STDOUT from the first program into the STDIN of the next program.
- They can be used to link together a series a simple programs in order to perform more complex tasks than they could do individually.
- Describe the filter commands:
- Simple filter commands allow the manipulation of text.
- These commands accomplish tasks such as: combining files, transforming the data in files, formatting text, displaying text, and summarizing data.
- Summarize the structure of regular expressions:
- Regular expressions are strings that describe other strings.
- They can contain normal alphanumeric characters, which match the exact same characters in the string they are describing. They can also contain several special symbols and symbol sets that match multiple different characters.
- Overall, regular expressions are a powerful pattern-matching tool used by many Linux programs.
Command Line Study and Review
- How to check environment variables (hint: env, echo $<name>), how to set environment variables (hint: export <name>=”<value>”, or <name>=”<value>” -> export <name>), how to delete environment variables (hint: unset <name>), and the common environment variables (hint: $TERM, etc).
- How to change shells and set the default shell.
- The difference between the default interactive shell and the default system shell (hint: /bin/sh points to the system shell).
- The difference between internal and external commands, which one takes precedence if both exist (hint: internal), how to determine if a command is internal / built-in (hint: builtin command) or external (hint: type command), and how to tell if both internal and external commands exist (hint: type -a) .
- What xterm, terminal, and konsole are and how they differ.
- What the system’s path is (hint: $PATH), how it stores its values (hint: colon-delimited list of directories), how to check its values, how to set its values, and how to run commands not on the path (hint: ./<program_name> or /<full_path>/<program_name>).
- Which permission / bit needs to be set in order to run a program / script (hint: executable bit), and how to change permissions (hint: chmod).
- The length filenames can be (hint: 255 characters on most systems).
- The shell shortcuts like command completion (tab complete) and history.
- How to navigate history:
- Ctrl+R to search backwards and Ctrl+S to search forward and cycle through matches.
- Ctrl+Q to quit a search (and stty -ixon to prevent hanging).
- Ctrl+G to terminate a search.
- !! to show and execute the last command used.
- !<number> to execute that command from history.
- history -c option to clear history.
- Where the history is stored (hint: ~/.bash_history), and how to prevent passwords and sensitive data from being saved in history (hint: only enter it as a response to a prompt, not as part of the command itself).
- How to navigate bash:
- Ctrl+A and Ctrl+E for start and end of line.
- Ctrl+D or Del to delete characters under the cursor.
- Backspace to delete characters to the left of the cursor.
- Ctrl+K to delete all text from the cursor to end of line.
- Ctrl+X -> Backspace to delete all text from the cursor to start of line.
- Ctrl+T to transpose (swap) the character under the cursor with the one before it.
- Esc -> T to transpose the two words before / under the cursor.
- Esc -> U for UPPERCASE, Esc -> L for lowercase, and Esc -> C for Capitalize Case.
- Ctrl+X -> Ctrl+E to open a full editor (defined in $FCEDIT or $EDITOR, defaults to Emacs).
- ‘set -o vi’ to set a vi-like mode in bash.
- Where the bash configuration files are (hint: ~/.bashrc and /etc/profile) and how to set them.
- How to find help documents and information on commands and options (hint: man, info, and help), how to search based on keyword (hint: man -k “<keywords>”), how to establish a keyword database (hint: the whatis database and the makewhatis command), and how to change the pager that displays the information (hint: man -P <path_to_pager> <command>).
- The sections of manual pages:
- 1 – Executable programs and shell commands.
- 2 – System calls provided by the kernel.
- 3 – Library calls provided by program libraries.
- 4 – Device files (usually stored in /dev).
- 5 – File formats.
- 6 – Games.
- 7 – Miscellaneous (macro packages, conventions, etc.).
- 8 – System administration commands (programs run mostly or exclusively by root).
- 9 – Kernel routines.
- How to navigate the less pager:
- Spacebar to move forward a page.
- Esc -> V to move back a page.
- Arrow keys to move up and down one line.
- / to search for text.
- Q to quit.
- How Linux treats all objects (hint: as files), what file descriptors are available (hint: 0, 1, 2), how to redirect input (STDIN) / output (STDOUT) / error (STDERR) streams (hint: >, >>, 2>, 2>>, &>, <, <<, <>), how to use a here document / heredoc (hint: command << eof_marker), and how to discard STDERR messages (hint: 2> /dev/null).
- How to use pipes to redirect and chain pipelines from multiple programs together (hint: prog1 | prog2).
- How to send STDOUT to both the screen and to another file or program (hint: tee).
- How to build new commands programmatically (hint: xargs), and what other options are available (hint: `
backticks`and $() enclosures ). - How to locate files (hint: find).
- How to find particular patterns of text within files (hint: grep).
- How to combine files (hint: cat), join files on a common field (hint: join), merge lines together (hint: paste), sort the content of files (hint: sort), delete duplicate lines (hint: uniq), and split files into multiple files (hint: split).
- How to convert between tabs and spaces (hint: expand, unexpand), convert a file to octal / hexadecimal / escaped ASCII (hint: od), and change characters in a file (hint: tr).
- How to format a file (hint: fmt), add line numbers (hint: nl, cat -b), how to prepare for printing (hint: pr), and how to print (hint: lpr).
- How to quickly view files without opening them in an editor (hint: head, tail).
- How to extract lines out of input (hint: cut).
- How to count the number of lines or size of a file (hint: wc).
- How to use Regular Expressions / regexp / regex:
- Bracket expression [abc]
- Range expression [0-9]
- Any single character (.)
- Start (^) and end ($) of line
- 0+ times (*), 1+ times (+), 0/1 time (?)
- Multiple possible matches ( this|that ).
- Subexpressions .*(\.digital)?
- Escaping special characters ( \|, etc. ).
- How to replace the contents of a file directly from the command line (hint: sed).
- Commands to know:
- uname
- cd
- rm
- pwd
- echo
- time
- set
- exit
- logout
- type
- builtin
- chmod
- env
- export
- unset
- man
- info
- less
- more
- find
- tee
- xargs
- cat / tac
- join
- paste
- sort
- tr
- expand / unexpand
- grep
- sed
- head
- tail
- cut
- wc
- man 7 regex
- ps
Foreword
I could not find any good options to put Fedora 25 Beta on an SD card using Windows, so I used VMWare Player with a Fedora 24. This tutorial will cover all of the steps I took.
Prerequisites
You will need:
- VMWare Workstation 12 Player
- Fedora 24 Workstation ISO
- Raspberry Pi 3
- Micro SD Card (16 GB+)*
- Fedora 25 Beta Image for Raspberry Pi 3
* Note: Format the SD card to FAT32
Steps
Configure VMWare Player
1. Start VMWare Player and select the option to ‘Create a New Virtual Machine’:
2. At the install prompt, select the ‘Installer disc image file (iso):’ option and click the Browse button to select the location of the Fedora 24 .iso file:
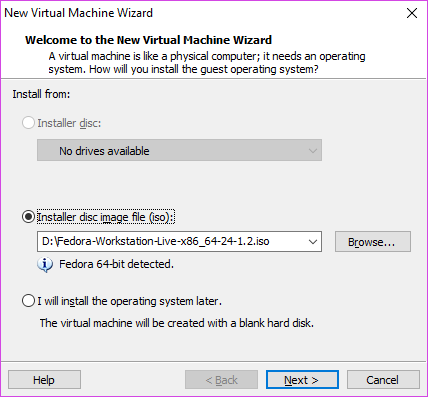
3. Give the virtual machine a name and a location to store its virtual hard drive:
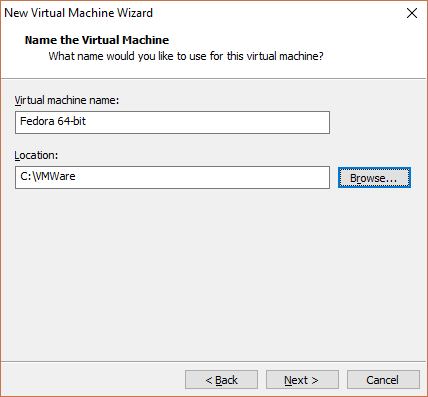
4. Set the capacity of the virtual hard drive to at least 20 GB, and select the option to store the virtual disk as a single file (for performance):
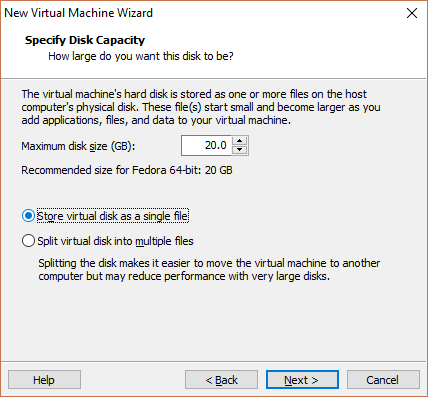
5. Click the Finish button to complete the setup and begin the installation of Fedora 24 Workstation:
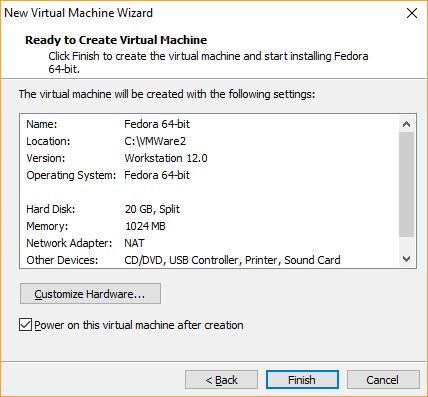
6. Follow the prompts on screen to complete the installation of Fedora 24:
7. After installation, shut down Fedora 24 and go back to VMWare Player to ‘Edit virtual machine settings’:
8. Select the Add button:
9. Select the Hard Disk option:
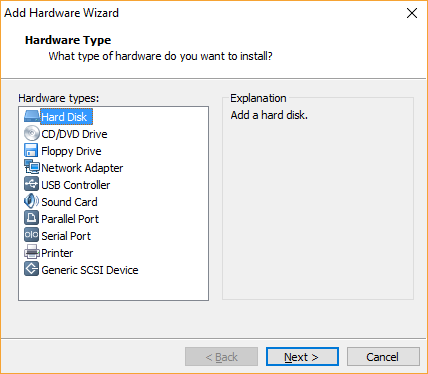
10. Select IDE:
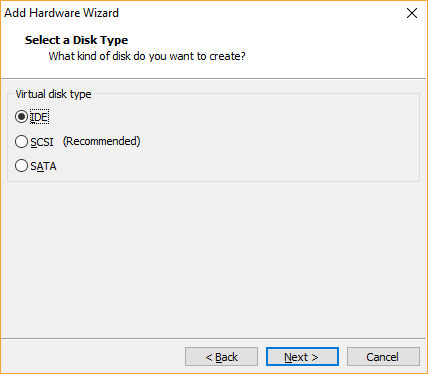
11. Select the option to use a physical disk:
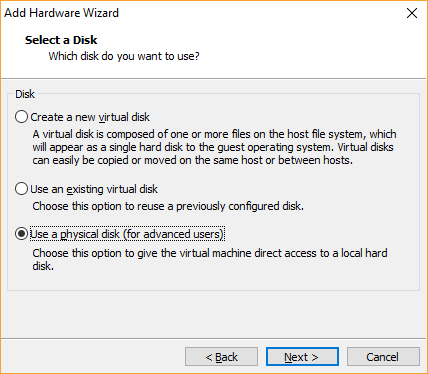
12. Select the PhysicalDrive corresponding to your SD card (generally the last one on the list):
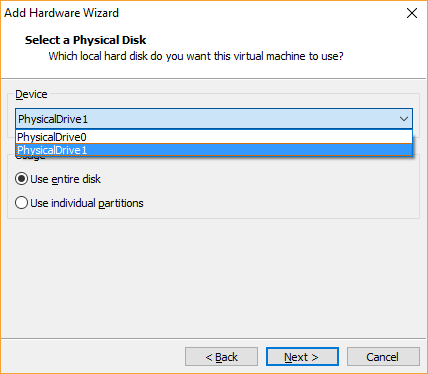
13. Give the disk file a name:
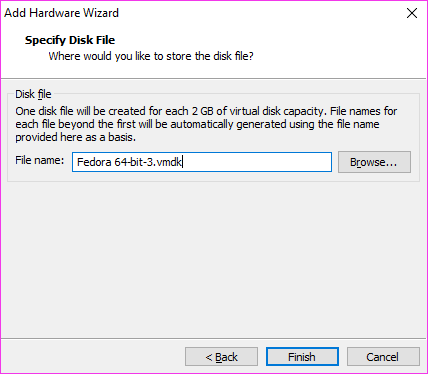
14. Verify the capacity appears to be correct for your SD card:
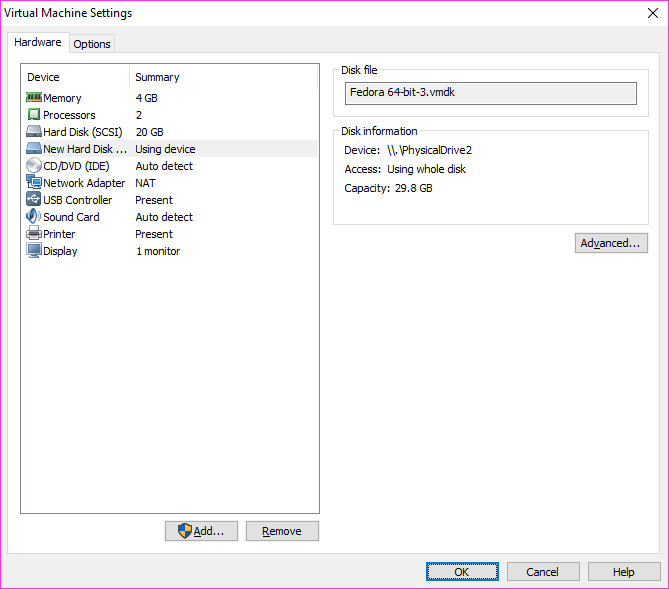
Locate the SD Card
15. Boot the VM, open Terminal, switch to the root user ($ sudo su –), and run the following commands to find the SD card:
# blkid
# lsblk
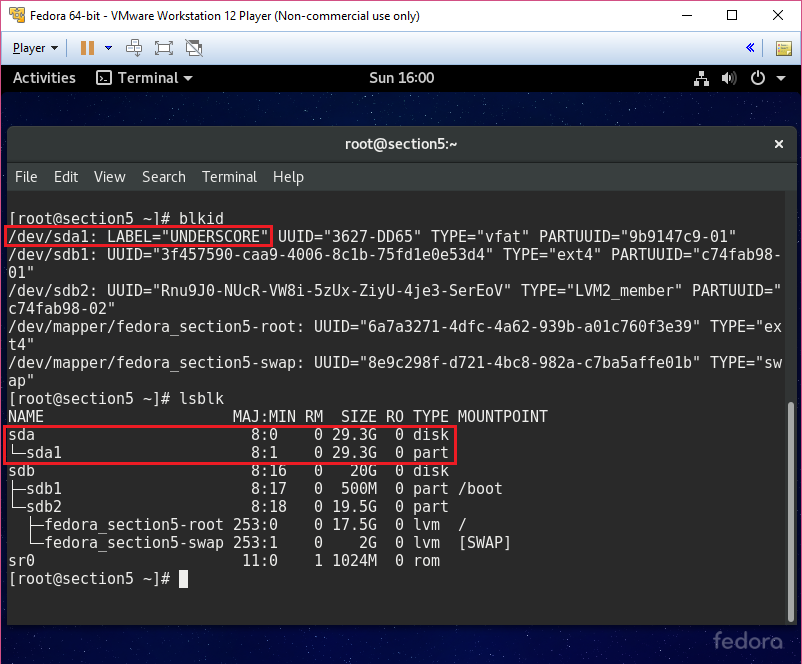
Notice that the SD card is showing up as sda, with the primary partition being sda1.
Download Fedora 25 Beta
16. Open Firefox, go to https://fedoraproject.org/wiki/Raspberry_Pi , and download either the Workstation or Server edition of Fedora 25 Beta:
I found the Workstation edition to work okay, but I preferred Server edition for performance
Install and Use the Fedora-ARM-Installer
17. Run the following command to install the Fedora-ARM-Installer:
# dnf install -y fedora-arm-installer
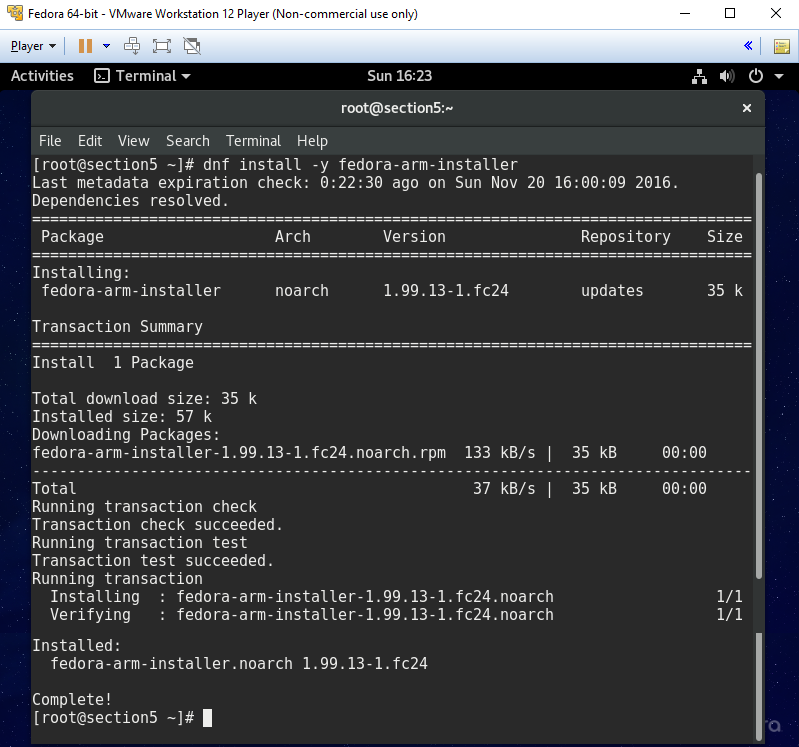
18. Copy the Fedora 25 Beta image file from your user’s Downloads directory to the root user’s home directory:
# mv /home/<user>/Downloads/Fedora-Server-armhfp-25_Beta-1.1-sda.raw.xz /root/
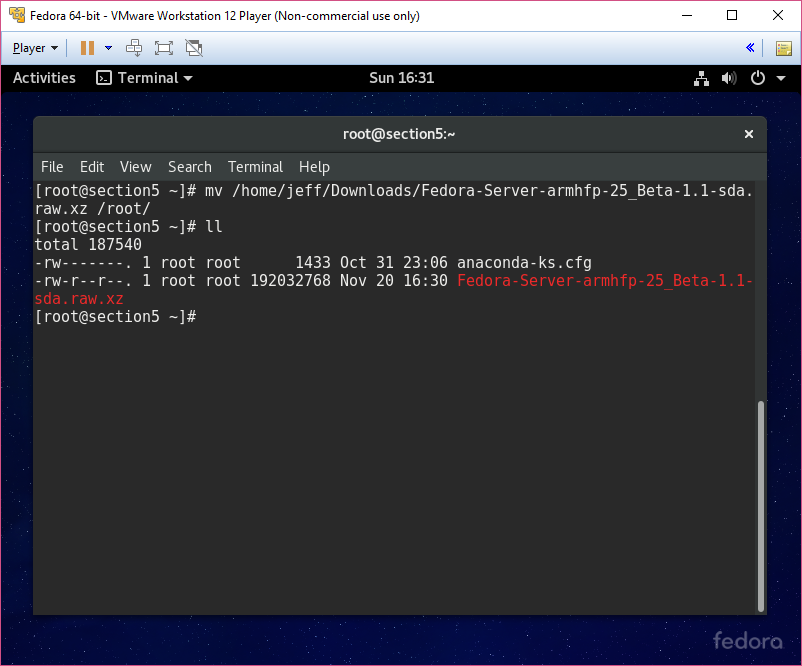
Tip: Pressing the Tab key in Linux will autocomplete filenames for you.
19. Run the following command to start the imaging process on the SD card:
# arm-image-installer –image=Fedora-Server-armhfp-25_Beta-1.1-sda.raw.xz –target=none –media=/dev/sda
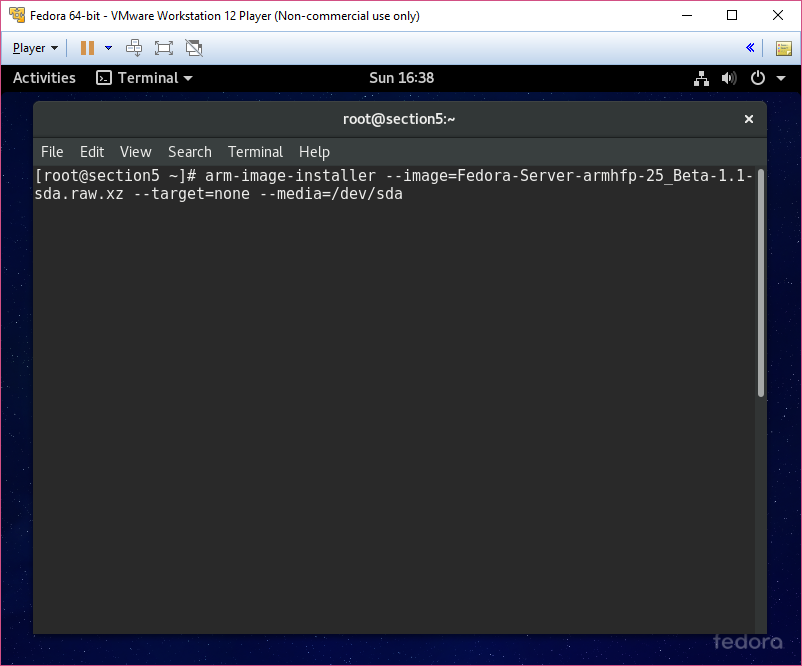
20. Type YES to proceed with the imaging:
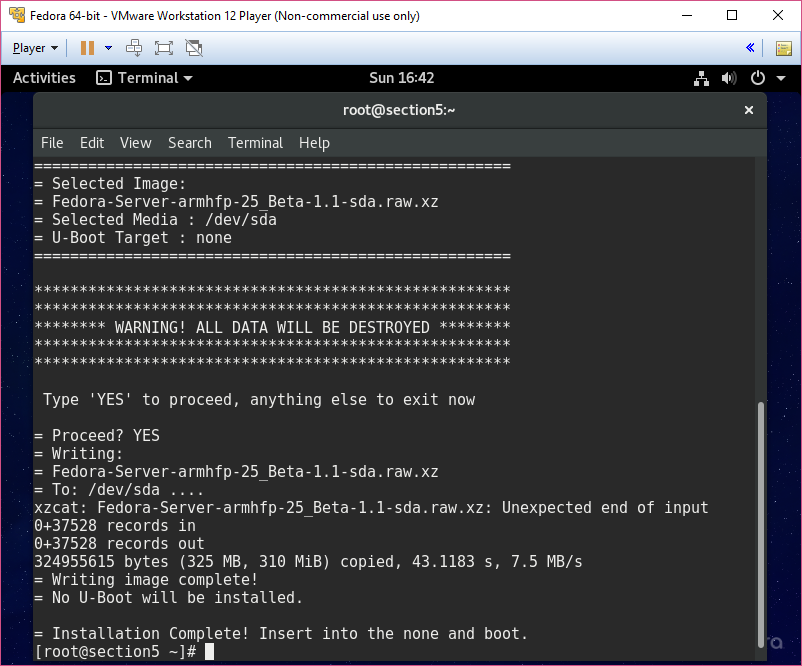
21. Shutdown the VM, pop the SD Card into the Pi, and enjoy!
Note: This last picture is from when I loaded the Fedora 25 Beta Workstation edition.
I figured the graphical interface makes a better picture to look at than the plain terminal.